h. Submit MNP Job via Console
In this section,
- Create the wikitext-2 dataset for training from huggingface
- Tokenize the dataset and shard it into multiple smaller files for data parallel distributed training
- Submit a MNP job through the AWS Batch console.
Creating the wikitext-2 dataset
The docker container that was built in the previous step establishes the environment and is the easiest way to create a working environment for creating the datasets.
- From the deploy folder, run the container locally and exec into the container
ubuntu@ip-172-31-9-117:~/CodeCommit/batch_multiarray_dl/build$ ls
Container-Root Dockerfile build.sh config.properties exec.sh pull.sh push.sh requirements.txt run.sh stop.sh
ubuntu@ip-172-31-9-117:~/CodeCommit/batch_multiarray_dl/build$ ./run.sh
Run Container in Daemon mode
1658b3185d28434a1b564c3d39bd7e2012c3f07d981b99dc59b2845ff760db02
ubuntu@ip-172-31-9-117:~/CodeCommit/batch_multiarray_dl/build$ ./exec.sh
Exec into Container
root@ip-172-31-9-117:/workspace#
- The preprocessing scripts are already packed into the /Model-References/PyTorch/nlp/pretraining/deepspeed-bert/data
root@12024b6e0389:/Model-References/PyTorch/nlp/pretraining/deepspeed-bert/data# bash create_datasets_from_start.sh wikitext-2
Download dataset wikitext-2
Download pretrained weights for bert_large_uncased
/Model-References/PyTorch/nlp/pretraining/deepspeed-bert/data
[nltk_data] Downloading package punkt to /root/nltk_data...
[nltk_data] Package punkt is already up-to-date!
Working Directory: /Model-References/PyTorch/nlp/pretraining/deepspeed-bert/data
Action: download
Dataset Name: google_pretrained_weights_bert_large_uncased
Directory Structure:
{ 'download': '/Model-References/PyTorch/nlp/pretraining/deepspeed-bert/data/download',
'extracted': '/Model-References/PyTorch/nlp/pretraining/deepspeed-bert/data/extracted',
'formatted': '/Model-References/PyTorch/nlp/pretraining/deepspeed-bert/data/formatted_one_article_per_line',
'hdf5': '/Model-References/PyTorch/nlp/pretraining/deepspeed-bert/data/hdf5_lower_case_1_seq_len_512_max_pred_20_masked_lm_prob_0.15_random_seed_12345_dupe_factor_5',
'sharded': '/Model-References/PyTorch/nlp/pretraining/deepspeed-bert/data/sharded_training_shards_256_test_shards_256_fraction_0.1',
'tfrecord': '/Model-References/PyTorch/nlp/pretraining/deepspeed-bert/data/tfrecord_lower_case_1_seq_len_512_max_pred_20_masked_lm_prob_0.15_random_seed_12345_dupe_factor_5'}
Downloading https://storage.googleapis.com/bert_models/2018_10_18/uncased_L-24_H-1024_A-16.zip
- After around 2 minutes of execution, two folders will be created under the data folder from which the command was executed
hdf5_lower_case_1_seq_len_128_max_pred_20_masked_lm_prob_0: Directory with sharded files for Pre Training Phase 1
hdf5_lower_case_1_seq_len_512_max_pred_20_masked_lm_prob_0: Directory with sharded files for Pre Training Phase 2
- In order to accomodate multiple datasets, we recommend the following structure
<EFS_ROOT>/hdf5_dataset/hdf5_lower_case_1_seq_len_512_max_pred_80_masked_lm_prob_0.15_random_seed_12345_dupe_factor_5/<datasetname>
- Move the wixitext-2 folder under each folders into the shared EFS (which is currently mounted at /efs)
/Model-References/PyTorch/nlp/pretraining/deepspeed-bert/data/hdf5_lower_case_1_seq_len_128_max_pred_20_masked_lm_prob_0.15_random_seed_12345_dupe_factor_5$ mv wikitext-2 /efs/hdf5_dataset/hdf5_lower_case_1_seq_len_128_max_pred_20_masked_lm_prob_0.15_random_seed_12345_dupe_factor_5/
/Model-References/PyTorch/nlp/pretraining/deepspeed-bert/data/hdf5_lower_case_1_seq_len_512_max_pred_80_masked_lm_prob_0.15_random_seed_12345_dupe_factor_5$ mv wikitext-2 /efs/hdf5_dataset/hdf5_lower_case_1_seq_len_512_max_pred_80_masked_lm_prob_0.15_random_seed_12345_dupe_factor_5/
-
The more comprehensive wikicorpus_en can be prepared based on the instructions in data_preparation. The corpus data needs to be downloaded (~100 GB+). The preprocessing steps will prepare the data using multiple passes. It would take around 8 - 12 hours to preprocess the data. - Since the data is not distributable directly, the end user has to prepare the data by downloading it from the source. This is not essential for the rest of the steps but has been included for the sake of completeness.
-
The hdf5 files are the primary inputs for the phase1 pretraining. After moving the folders into the hdf5_dataset folder, the resulting folder structure is shown below
-- /mnt/efs/hdf5_dataset ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
58.1 GiB [################################] /hdf5_lower_case_1_seq_len_512_max_pred_80_masked_lm_prob_0.15_random_seed_12345_dupe_factor_5
50.4 GiB [########################### ] /hdf5_lower_case_1_seq_len_128_max_pred_20_masked_lm_prob_0.15_random_seed_12345_dupe_factor_5
--- /efs/hdf5_dataset/hdf5_lower_case_1_seq_len_128_max_pred_20_masked_lm_prob_0.15_random_seed_12345_dupe_factor_5 --------------------------------------------------------------------------------------------------------------------------------------------
50.4 GiB [##########] /wikicorpus_en
44.3 MiB [ ] /wikitext-2
--- /efs/hdf5_dataset/hdf5_lower_case_1_seq_len_128_max_pred_20_masked_lm_prob_0.15_random_seed_12345_dupe_factor_5/wikitext-2 ---------------------------------------------------------------------------------------------------------------------------------
/..
276.0 KiB [##########] wikitext-2_training_1.hdf5
264.0 KiB [######### ] wikitext-2_training_0.hdf5
232.0 KiB [######## ] wikitext-2_training_2.hdf5
228.0 KiB [######## ] wikitext-2_training_3.hdf5
220.0 KiB [####### ] wikitext-2_training_18.hdf5
....
208.0 KiB [####### ] wikitext-2_training_7.hdf5
196.0 KiB [####### ] wikitext-2_training_13.hdf5
192.0 KiB [###### ] wikitext-2_training_25.hdf5
High Level MNP Job Setup
In a production environment, it’s important to efficiently execute the compute workload with multi-node parallel jobs. Most of the optimization is on the application layer and how efficiently the Message Passing Interface (MPI) ranks (MPI and OpenMP threads) are distributed across nodes.
The key requirements for running a MNP job on AWS Batch is a
- Dockerized image with
- application libraries, scripts, and code
- MPI stack for the tightly coupled communication layer
- Docker to Docker Communication
- Passwordless ssh ability from one node to another
- Running child Docker containers need to pass container IP address information to the master node to fill out the MPI host file
- Wrapper script for the MPI orchestration (Packaged into the container)
The undifferentiated heavy lifting that AWS Batch provides is the Docker-to-Docker communication across nodes using Amazon ECS task networking. With multi-node parallel jobs, the ECS container receives environmental variables from the backend, which can be used to establish which running container is the master and which is the child.
| ENV Variable | Description |
|---|---|
| AWS_BATCH_JOB_MAIN_NODE_INDEX | The designation of the master node in a multi-node parallel job. This is the main node in which the MPI job is launched. |
| AWS_BATCH_JOB_MAIN_NODE_PRIVATE_IPV4_ADDRESS | The IPv4 address of the main node. This is presented in the environment for all children nodes. |
| AWS_BATCH_JOB_NUM_NODES | The number of nodes launched as part of the node group for your multi-node parallel job. |
When the docker container starts up, a supervisor script executes the commands in order
- SSHD Setup
- Triggers the ssh-daemon to start in Port 2022
- Point the id_rsa to the “same” key that is present in all the containers as a part of the build process
- This is fundamental to enable passwordless ssh across different containers
- Discovery of Child & Master workers
- Environment variables are used to determine if the container instance is a Child or a Master. For example, If AWS_BATCH_JOB_MAIN_NODE_INDEX = AWS_BATCH_JOB_NODE_INDEX, then this is the main node.
- MNP automatically assigns each Container with an IP Address that is needed for container task networking
- The code in prep_mpi_run.sh provides the MPI synchronization
- Incorporate simple health checks on the instance being launched into the pool. Any bad instances can be tagged and removed off the pool so that it does not result in a failed overall run.
- Broadly, there are two different types of action
- Master Node: Will wait for all the child nodes to report their IP
- Child Node: Will report their Container IP address obtained via (hostname -i)
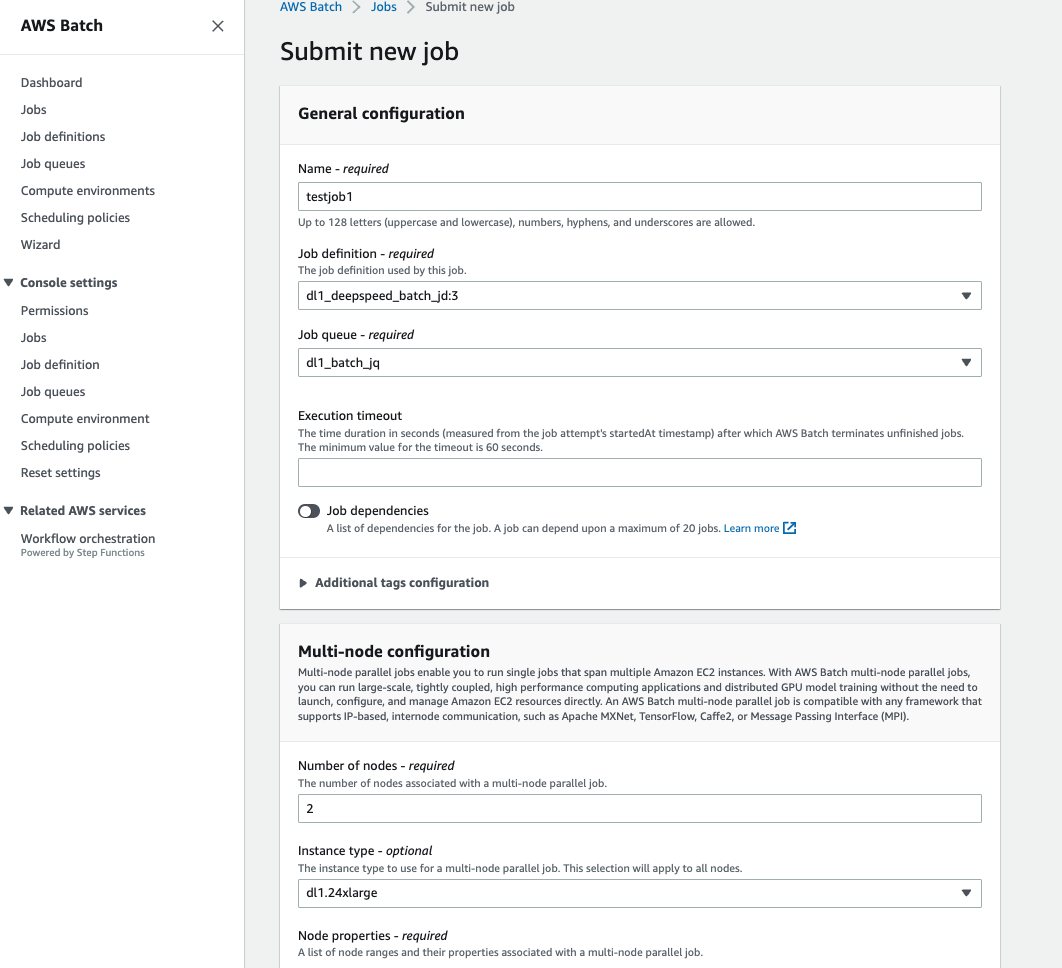
Submit a new Job
From the AWS Batch Console, click on Job Definition and then the MNP job definition which was just created.
- Click on new submit a new job
- Set the Name as testjob
- Set the JobQueue as dl1_mnp_jq (from the downselect)
- Multi Node Configuration
- Number of Nodes (Can be modified to the total number of nodes we want in our training)
- Leave the others at default (since they are automatically picked up from the job definition)
Screenshot of the Job submission dialog is shown below
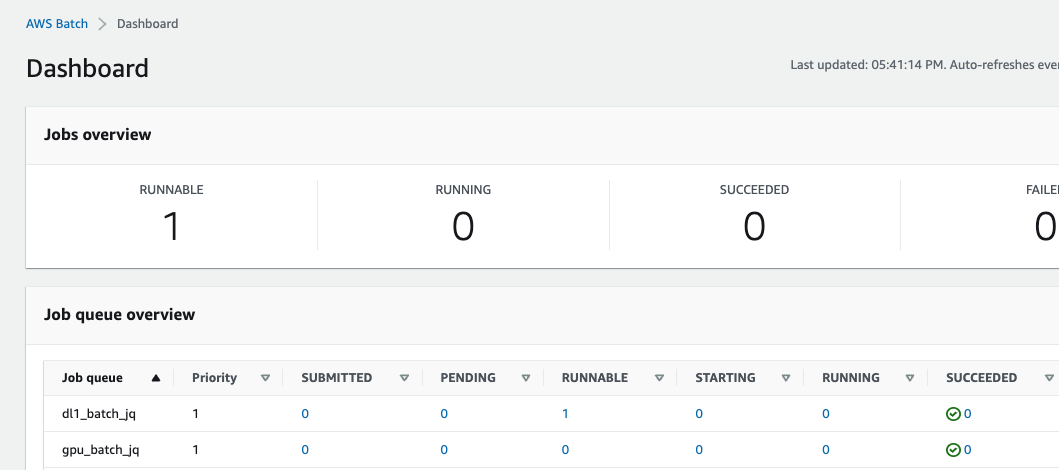
After the job submit, the job will go to a Runnable State
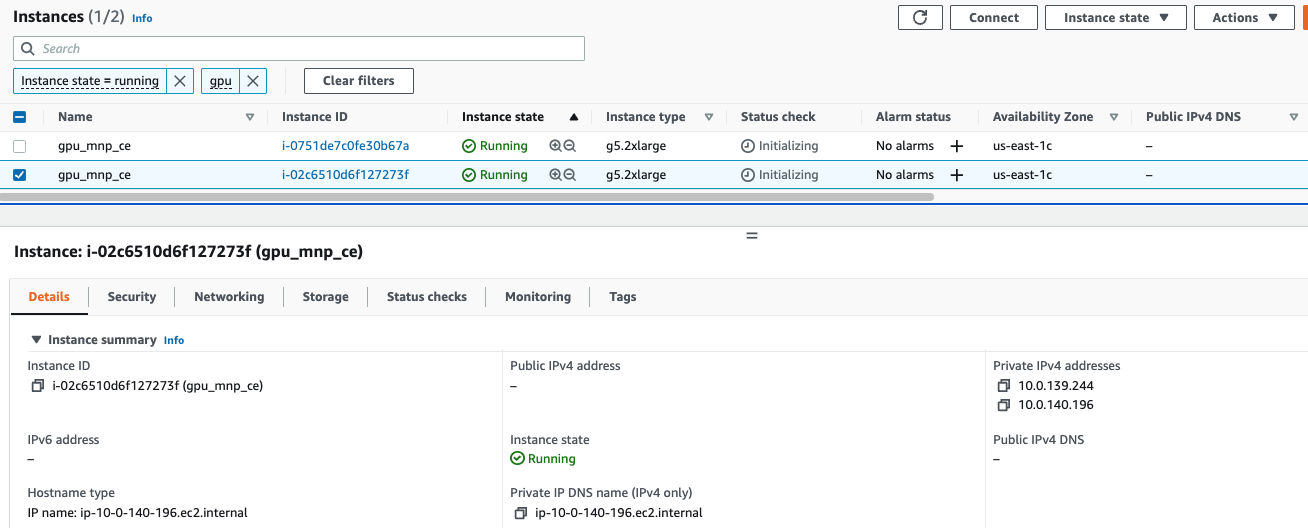
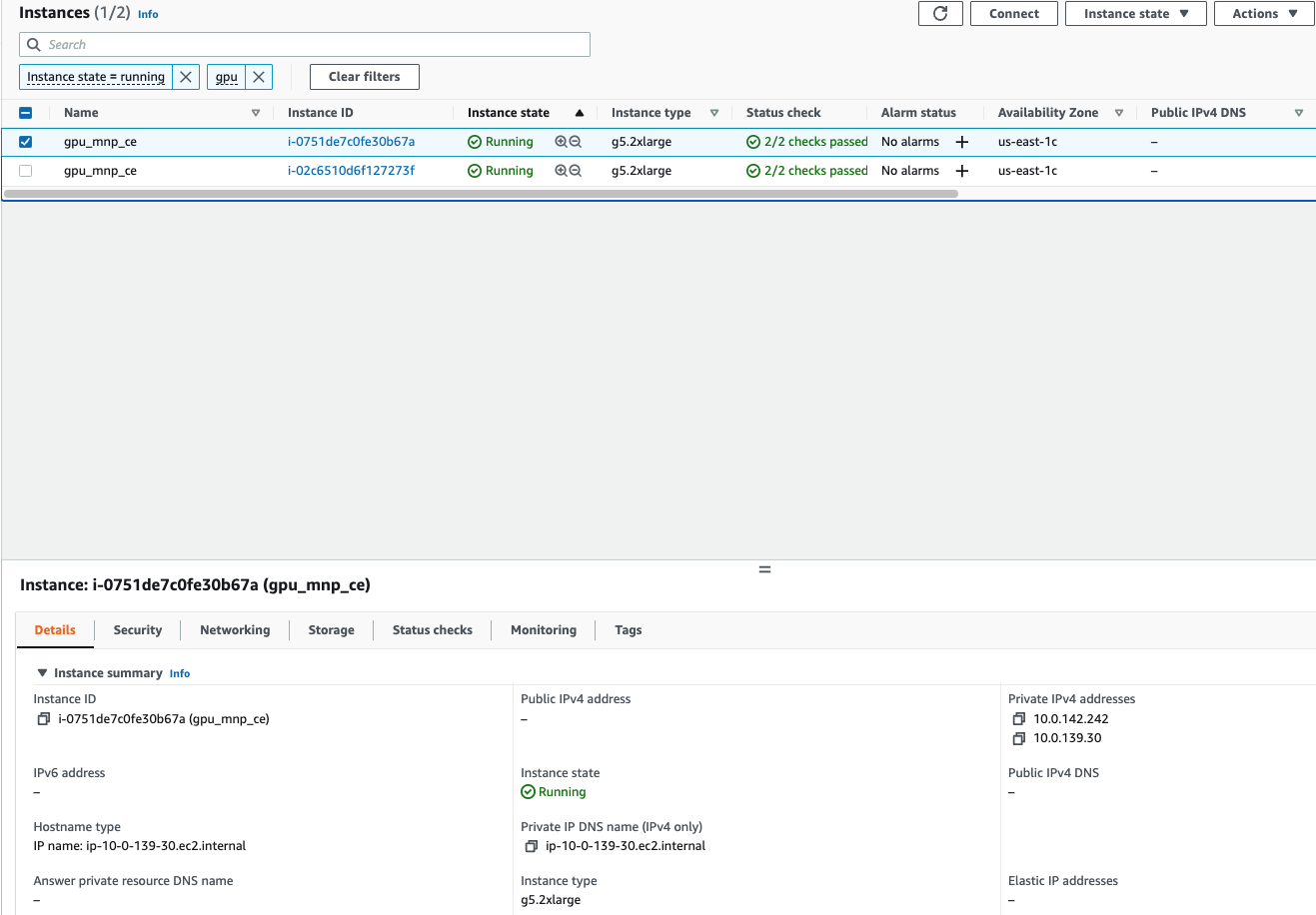
Sequence of Instance Launch and IP assignment
Even though both the instances startup, the master node will be the first to pull the container. This is clearly seen by the 2 private ip’s that get assigned to the master node (1 for the instance and 1 for the container). At the same time, the child node has only the instance ip
Master Node having 2 ip’s
At the same time the Child Node has only 1 ip
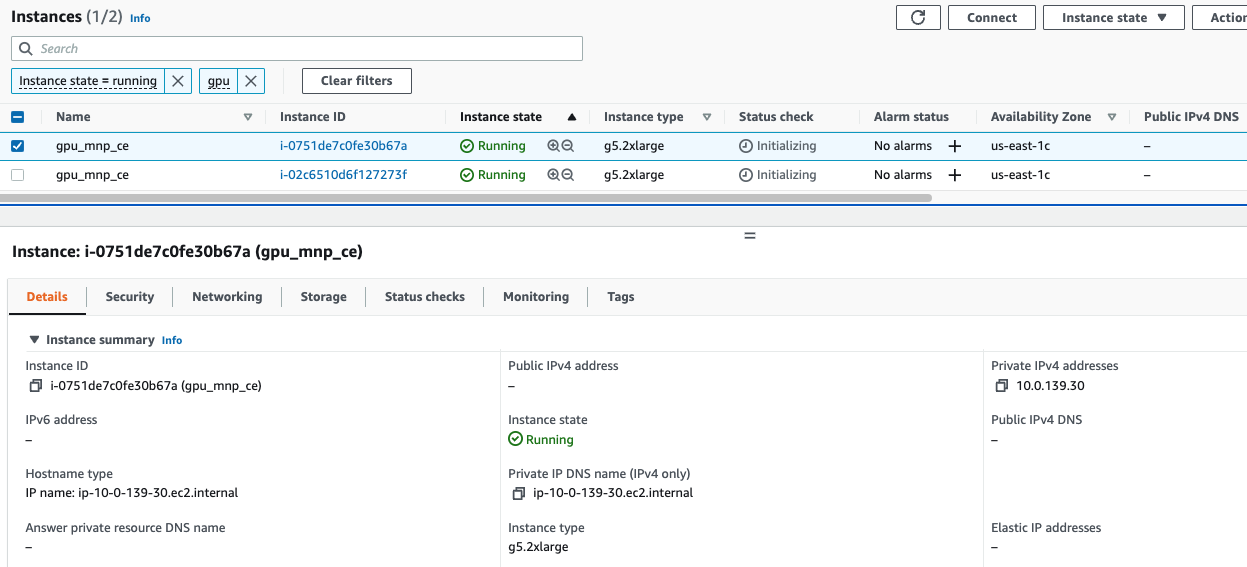
After the Master has started up, the containers will be downloaded onto the child nodes and it will also get 2 IP’s
Logging into the Master Node
-
Determine the ssh connect information from the instance by right clicking on the instance in the EC2 console
-
Use the Cloud9 to connect to your Master Node. The Cloud9 instance is in your public subnet and can be used to connect to your instances in the private subnet. You have to copy your *.pem file to your Cloud9 instance to use it as credentials for the ssh
ssh -i "xxxxxxx.pem" ec2-user@10.0.140.196
__| __| __|
_| ( \__ \ Amazon Linux 2 (ECS Optimized)
____|\___|____/
For documentation, visit http://aws.amazon.com/documentation/ecs
14 package(s) needed for security, out of 30 available
Run "sudo yum update" to apply all updates.
- Verify the Containers running on the master node
[ec2-user@ip-172-31-81-48 ~]$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
e661aa6a2cbb 01234567890.dkr.ecr.us-east-1.amazonaws.com/dl1_bert_train:v1 "/bin/sh -c /entry-p…" 4 minutes ago Up 4 minutes ecs-dl1_deepspeed_batch_jd_0-1-3-default-b4cea0caf786d6edec01
189223288b98 amazon/amazon-ecs-pause:0.1.0 "/pause" 5 minutes ago Up 5 minutes ecs-dl1_deepspeed_batch_jd_0-1-3-internalecspause-a8e8d4acaa82acaefa01
5c7add94c160 amazon/amazon-ecs-agent:latest "/agent" 6 minutes ago Up 6 minutes (healthy) ecs-agent
- Check the logs of the container. Initially the master node is only part of the pool and it waits until all the child nodes join the pool
[ec2-user@ip-10-0-140-196 ~]$ docker logs aac
2022-07-26 18:55:34,459 CRIT Supervisor is running as root. Privileges were not dropped because no user is specified in the config file. If you intend to run as root, you can set user=root in the config file to avoid this message.
2022-07-26 18:55:34,460 INFO supervisord started with pid 8
2022-07-26 18:55:35,462 INFO spawned: 'sshd' with pid 10
2022-07-26 18:55:35,463 INFO spawned: 'synchronize' with pid 11
prep_mpi_run.sh - Running synchronize as the main node
2022-07-26 18:55:35,466 INFO success: synchronize entered RUNNING state, process has stayed up for > than 0 seconds (startsecs)
prep_mpi_run.sh - main
prep_mpi_run.sh - Running as master node
prep_mpi_run.sh - master details -> 10.0.139.244:1
prep_mpi_run.sh - 1 out of 2 nodes joined, check again in 1 second
2022-07-26 18:55:36,473 INFO success: sshd entered RUNNING state, process has stayed up for > than 1 seconds (startsecs)
prep_mpi_run.sh - 1 out of 2 nodes joined, check again in 1 second
.....
prep_mpi_run.sh - 1 out of 2 nodes joined, check again in 1 second
- After the Child node starts up and the container is up and running, it will report its IP to the master. At this point the log file in the master would confirm “successful” join by all the child nodes and the hostfile would be created in /tmp/hostfile
prep_mpi_run.sh - 1 out of 2 nodes joined, check again in 1 second
prep_mpi_run.sh - All nodes successfully joined
172.31.81.82 slots=8
172.31.94.102 slots=8
prep_mpi_run.sh - executing main MPIRUN workflow
Tue Jul 26 19:00:07 UTC 2022
Tue Jul 26 19:01:07 UTC 2022
In this case,
- The first IP is for the container on the master node
- The second IP is the container on the child node
- If you have more than 2 nodes, the IP’s will be captured in the hostfile
Exec into the Master Node to start training job
- Exec into the Master Node using docker exec. You will be in the /workspace folder
- The Dockerfile downloads the deepspeed-bert (for DL1) and assembles the scripts in the /Model-References folder
root@ip-172-31-81-82:/Model-References/PyTorch/nlp/pretraining/deepspeed-bert# ls -lrt
total 224
-rwxr-xr-x 1 root root 1816 Jul 13 00:15 utils.py
-rwxr-xr-x 1 root root 15145 Jul 13 00:15 tokenization.py
-rw-r--r-- 1 root root 8506 Jul 13 00:15 tensor_logger.py
-rwxr-xr-x 1 root root 5022 Jul 13 00:15 schedulers.py
-rwxr-xr-x 1 root root 33487 Jul 13 00:15 run_pretraining.py
-rwxr-xr-x 1 root root 295 Jul 13 00:15 requirements.txt
-rw-r--r-- 1 root root 12273 Jul 13 00:15 README.md
-rwxr-xr-x 1 root root 62647 Jul 13 00:15 modeling.py
-rw-r--r-- 1 root root 11470 Jul 13 00:15 LICENSE
-rwxr-xr-x 1 root root 9658 Jul 13 00:15 lamb.py
-rwxr-xr-x 1 root root 10353 Jul 13 00:15 lamb_exp.py
-rwxr-xr-x 1 root root 8909 Jul 13 00:15 file_utils.py
drwxr-xr-x 2 root root 290 Jul 13 00:15 data
-rwxr-xr-x 1 root root 17612 Jul 13 00:15 create_pretraining_data.py
drwxr-xr-x 1 root root 302 Jul 13 21:55 scripts
root@ip-172-31-81-82:/Model-References/PyTorch/nlp/pretraining/deepspeed-bert# ls -lrt scripts/
total 48
-rwxr-xr-x 1 root root 1544 Jul 13 00:15 run_bert_1.5b_8x.sh
-rwxr-xr-x 1 root root 1735 Jul 13 00:15 run_bert_1.5b_32x.sh
-rw-rw-r-- 1 root root 45 Jul 13 00:17 hostsfile
-rw-rw-r-- 1 root root 215 Jul 13 00:17 deepspeed_config_bert_tiny.json
-rw-rw-r-- 1 root root 357 Jul 13 00:17 deepspeed_config_bert_large.json
-rw-rw-r-- 1 root root 359 Jul 13 00:17 deepspeed_config_bert_1.5b.json
-rw-rw-r-- 1 root root 330 Jul 13 00:17 bert_tiny_config.json
-rw-rw-r-- 1 root root 340 Jul 13 00:17 bert_large_config.json
-rw-rw-r-- 1 root root 372 Jul 13 00:17 bert_1.5b_config.json
-rwxrwxr-x 1 root root 2262 Jul 13 21:37 run_bert_tiny.sh
-rwxrwxr-x 1 root root 2286 Jul 13 21:55 run_bert_large.sh
-rwxrwxr-x 1 root root 2334 Jul 13 21:55 run_bert_1.5b.sh
Specify Dataset for the Scripts
BERT Tiny Model + DeepSpeed
A tiny model of the BERT is prepared by using the bert_tiny_config.json & deepspeed_config_bert_tiny.json with only 2 layers to quickly assess deepspeed functionality. It is almost equivalent to the helloworld program.
- The launch script is run_bert_tiny.sh with just 1 node and 1 hpu being used for the job
# Params: DeepSpeed
NUM_NODES=1
NGPU_PER_NODE=1
- The sharded dataset is specified in the launch script
# Dataset Params
EFS_FOLDER=/mnt/efs
SHARED_FOLDER=${EFS_FOLDER}
data_dir=${SHARED_FOLDER}/hdf5_dataset
# DATA_DIR=${data_dir}/hdf5_lower_case_1_seq_len_128_max_pred_20_masked_lm_prob_0.15_random_seed_12345_dupe_factor_5/wikicorpus_en
DATA_DIR=${data_dir}/hdf5_lower_case_1_seq_len_128_max_pred_20_masked_lm_prob_0.15_random_seed_12345_dupe_factor_5/wikitext-2
- Here is the output of running the training script
root@ip-172-31-81-82:/Model-References/PyTorch/nlp/pretraining/deepspeed-bert/scripts# ./run_bert_tiny.sh
[2022-08-03 03:49:22,611] [WARNING] [runner.py:159:fetch_hostfile] Unable to find hostfile, will proceed with training with local resources only.
Namespace(autotuning='', exclude='', force_multi=False, hostfile='/job/hostfile', include='', launcher='pdsh', launcher_args='', master_addr='172.31.81.82', master_port=29500, module=False, no_local_rank=True, no_python=True, num_gpus=1, num_nodes=1, save_pid=False, use_hpu=False, user_args=['-c', 'source /activate ; cd /Model-References/PyTorch/nlp/pretraining/deepspeed-bert/scripts && python -u ../run_pretraining.py --use_hpu --resume_from_checkpoint --do_train --bert_model=bert-base-uncased --config_file=./bert_tiny_config.json --json-summary=../results/bert_tiny/dllogger.json --output_dir=../results/bert_tiny/checkpoints --seed=12439 --optimizer=nvlamb --use_lr_scheduler --input_dir=/mnt/efs/hdf5_dataset/hdf5_lower_case_1_seq_len_128_max_pred_20_masked_lm_prob_0.15_random_seed_12345_dupe_factor_5/wikitext-2 --max_seq_length 128 --max_predictions_per_seq=20 --max_steps=5000 --warmup_proportion=0.2843 --num_steps_per_checkpoint=10000 --learning_rate=0.006 --deepspeed --deepspeed_config=./deepspeed_config_bert_tiny.json'], user_script='/usr/bin/bash')
[2022-08-03 03:49:22,612] [INFO] [runner.py:466:main] cmd = /usr/bin/python3 -u -m deepspeed.launcher.launch --world_info=eyJsb2NhbGhvc3QiOiBbMF19 --master_addr=127.0.0.1 --master_port=29500 --no_python --no_local_rank /usr/bin/bash -c source /activate ; cd /Model-References/PyTorch/nlp/pretraining/deepspeed-bert/scripts && python -u ../run_pretraining.py --use_hpu --resume_from_checkpoint --do_train --bert_model=bert-base-uncased --config_file=./bert_tiny_config.json --json-summary=../results/bert_tiny/dllogger.json --output_dir=../results/bert_tiny/checkpoints --seed=12439 --optimizer=nvlamb --use_lr_scheduler --input_dir=/mnt/efs/hdf5_dataset/hdf5_lower_case_1_seq_len_128_max_pred_20_masked_lm_prob_0.15_random_seed_12345_dupe_factor_5/wikitext-2 --max_seq_length 128 --max_predictions_per_seq=20 --max_steps=5000 --warmup_proportion=0.2843 --num_steps_per_checkpoint=10000 --learning_rate=0.006 --deepspeed --deepspeed_config=./deepspeed_config_bert_tiny.json
[2022-08-03 03:49:23,065] [INFO] [launch.py:104:main] WORLD INFO DICT: {'localhost': [0]}
[2022-08-03 03:49:23,065] [INFO] [launch.py:110:main] nnodes=1, num_local_procs=1, node_rank=0
[2022-08-03 03:49:23,065] [INFO] [launch.py:123:main] global_rank_mapping=defaultdict(<class 'list'>, {'localhost': [0]})
[2022-08-03 03:49:23,065] [INFO] [launch.py:124:main] dist_world_size=1
/usr/bin/bash: /activate: No such file or directory
Distributed training with backend=hccl, device=hpu, local_rank=0
[2022-08-03 03:49:23,663] [INFO] [distributed.py:46:init_distributed] Initializing torch distributed with backend: hccl
DLL 2022-08-03 03:49:23.664750 - PARAMETER Config : ["Namespace(bert_model='bert-base-uncased', config_file='./bert_tiny_config.json', constant_proportion=0.0, deepscale=False, deepscale_config=None, deepspeed=True, deepspeed_config='./deepspeed_config_bert_tiny.json', deepspeed_mpi=False, disable_progress_bar=False, do_train=True, init_loss_scale=1048576, input_dir='/mnt/efs/hdf5_dataset/hdf5_lower_case_1_seq_len_128_max_pred_20_masked_lm_prob_0.15_random_seed_12345_dupe_factor_5/wikitext-2', json_summary='../results/bert_tiny/dllogger.json', learning_rate=0.006, local_rank=0, log_bwd_grads=False, log_freq=1.0, log_fwd_activations=False, log_model_inputs=False, loss_scale=0.0, max_predictions_per_seq=20, max_seq_length=128, max_steps=5000.0, no_cuda=False, num_steps_per_checkpoint=10000, num_train_epochs=3.0, optimizer='nvlamb', output_dir='../results/bert_tiny/checkpoints', phase1_end_step=7038, phase2=False, rank=0, resume_from_checkpoint=True, resume_step=-1, scheduler_degree=1.0, seed=12439, skip_checkpoint=False, steps_this_run=5000.0, tensor_logger_max_iterations=0, tensor_logger_path=None, use_env=False, use_hpu=True, use_lazy_mode=True, use_lr_scheduler=True, warmup_proportion=0.2843, world_size=1, zero_optimization=False)"]
Using NVLamb
Using PolyWarmUpScheduler with args={'warmup': 0.2843, 'total_steps': 5000.0, 'degree': 1.0, 'constant': 0.0}
[2022-08-03 03:49:24,776] [INFO] [logging.py:69:log_dist] [Rank 0] DeepSpeed info: version=0.6.1+0f2b744, git-hash=0f2b744, git-branch=v1.5.0
[2022-08-03 03:49:25,349] [INFO] [engine.py:310:__init__] DeepSpeed Flops Profiler Enabled: False
[2022-08-03 03:49:25,349] [INFO] [engine.py:1096:_configure_optimizer] Removing param_group that has no 'params' in the client Optimizer
[2022-08-03 03:49:25,349] [INFO] [engine.py:1102:_configure_optimizer] Using client Optimizer as basic optimizer
[2022-08-03 03:49:25,350] [INFO] [engine.py:1118:_configure_optimizer] DeepSpeed Basic Optimizer = NVLAMB
[2022-08-03 03:49:25,350] [INFO] [logging.py:69:log_dist] [Rank 0] DeepSpeed Final Optimizer = NVLAMB
[2022-08-03 03:49:25,350] [INFO] [engine.py:822:_configure_lr_scheduler] DeepSpeed using client LR scheduler
[2022-08-03 03:49:25,350] [INFO] [logging.py:69:log_dist] [Rank 0] DeepSpeed LR Scheduler = <schedulers.PolyWarmUpScheduler object at 0x7f3e10209df0>
[2022-08-03 03:49:25,350] [INFO] [logging.py:69:log_dist] [Rank 0] step=0, skipped=0, lr=[4.220893422441084e-06, 4.220893422441084e-06], mom=[(0.9, 0.999), (0.9, 0.999)]
[2022-08-03 03:49:25,350] [INFO] [config.py:1068:print] DeepSpeedEngine configuration:
[2022-08-03 03:49:25,350] [INFO] [config.py:1072:print] activation_checkpointing_config {
"partition_activations": false,
"contiguous_memory_optimization": false,
"cpu_checkpointing": false,
"number_checkpoints": null,
"synchronize_checkpoint_boundary": false,
"profile": false
}
[2022-08-03 03:49:25,350] [INFO] [config.py:1072:print] aio_config ................... {'block_size': 1048576, 'queue_depth': 8, 'thread_count': 1, 'single_submit': False, 'overlap_events': True}
[2022-08-03 03:49:25,350] [INFO] [config.py:1072:print] amp_enabled .................. False
[2022-08-03 03:49:25,350] [INFO] [config.py:1072:print] amp_params ................... False
[2022-08-03 03:49:25,350] [INFO] [config.py:1072:print] autotuning_config ............ {
"enabled": false,
"start_step": null,
"end_step": null,
"metric_path": null,
"arg_mappings": null,
"metric": "throughput",
"model_info": null,
"results_dir": null,
"exps_dir": null,
"overwrite": true,
"fast": true,
"start_profile_step": 3,
"end_profile_step": 5,
"tuner_type": "gridsearch",
"tuner_early_stopping": 5,
"tuner_num_trials": 50,
"model_info_path": null,
"mp_size": 1,
"max_train_batch_size": null,
"min_train_batch_size": 1,
"max_train_micro_batch_size_per_gpu": 1.024000e+03,
"min_train_micro_batch_size_per_gpu": 1,
"num_tuning_micro_batch_sizes": 3
}
[2022-08-03 03:49:25,350] [INFO] [config.py:1072:print] bfloat16_enabled ............. False
[2022-08-03 03:49:25,350] [INFO] [config.py:1072:print] checkpoint_tag_validation_enabled True
[2022-08-03 03:49:25,351] [INFO] [config.py:1072:print] checkpoint_tag_validation_fail False
[2022-08-03 03:49:25,351] [INFO] [config.py:1072:print] communication_data_type ...... None
[2022-08-03 03:49:25,351] [INFO] [config.py:1072:print] curriculum_enabled ........... False
[2022-08-03 03:49:25,351] [INFO] [config.py:1072:print] curriculum_params ............ False
[2022-08-03 03:49:25,351] [INFO] [config.py:1072:print] dataloader_drop_last ......... False
[2022-08-03 03:49:25,351] [INFO] [config.py:1072:print] disable_allgather ............ False
[2022-08-03 03:49:25,351] [INFO] [config.py:1072:print] dump_state ................... False
[2022-08-03 03:49:25,351] [INFO] [config.py:1072:print] dynamic_loss_scale_args ...... None
[2022-08-03 03:49:25,351] [INFO] [config.py:1072:print] eigenvalue_enabled ........... False
[2022-08-03 03:49:25,351] [INFO] [config.py:1072:print] eigenvalue_gas_boundary_resolution 1
[2022-08-03 03:49:25,351] [INFO] [config.py:1072:print] eigenvalue_layer_name ........ bert.encoder.layer
[2022-08-03 03:49:25,351] [INFO] [config.py:1072:print] eigenvalue_layer_num ......... 0
[2022-08-03 03:49:25,351] [INFO] [config.py:1072:print] eigenvalue_max_iter .......... 100
[2022-08-03 03:49:25,351] [INFO] [config.py:1072:print] eigenvalue_stability ......... 1e-06
[2022-08-03 03:49:25,351] [INFO] [config.py:1072:print] eigenvalue_tol ............... 0.01
[2022-08-03 03:49:25,351] [INFO] [config.py:1072:print] eigenvalue_verbose ........... False
[2022-08-03 03:49:25,351] [INFO] [config.py:1072:print] elasticity_enabled ........... False
[2022-08-03 03:49:25,351] [INFO] [config.py:1072:print] flops_profiler_config ........ {
"enabled": false,
"profile_step": 1,
"module_depth": -1,
"top_modules": 1,
"detailed": true,
"output_file": null
}
[2022-08-03 03:49:25,351] [INFO] [config.py:1072:print] fp16_enabled ................. False
[2022-08-03 03:49:25,351] [INFO] [config.py:1072:print] fp16_master_weights_and_gradients False
[2022-08-03 03:49:25,351] [INFO] [config.py:1072:print] fp16_mixed_quantize .......... False
[2022-08-03 03:49:25,351] [INFO] [config.py:1072:print] global_rank .................. 0
[2022-08-03 03:49:25,351] [INFO] [config.py:1072:print] gradient_accumulation_steps .. 1024
[2022-08-03 03:49:25,351] [INFO] [config.py:1072:print] gradient_clipping ............ 0.0
[2022-08-03 03:49:25,351] [INFO] [config.py:1072:print] gradient_predivide_factor .... 1.0
[2022-08-03 03:49:25,351] [INFO] [config.py:1072:print] initial_dynamic_scale ........ 4294967296
[2022-08-03 03:49:25,351] [INFO] [config.py:1072:print] loss_scale ................... 0
[2022-08-03 03:49:25,351] [INFO] [config.py:1072:print] memory_breakdown ............. False
[2022-08-03 03:49:25,351] [INFO] [config.py:1072:print] optimizer_legacy_fusion ...... False
[2022-08-03 03:49:25,351] [INFO] [config.py:1072:print] optimizer_name ............... None
[2022-08-03 03:49:25,351] [INFO] [config.py:1072:print] optimizer_params ............. None
[2022-08-03 03:49:25,351] [INFO] [config.py:1072:print] pipeline ..................... {'stages': 'auto', 'partition': 'best', 'seed_layers': False, 'activation_checkpoint_interval': 0}
[2022-08-03 03:49:25,351] [INFO] [config.py:1072:print] pld_enabled .................. False
[2022-08-03 03:49:25,351] [INFO] [config.py:1072:print] pld_params ................... False
[2022-08-03 03:49:25,351] [INFO] [config.py:1072:print] prescale_gradients ........... False
[2022-08-03 03:49:25,351] [INFO] [config.py:1072:print] quantize_change_rate ......... 0.001
[2022-08-03 03:49:25,351] [INFO] [config.py:1072:print] quantize_groups .............. 1
[2022-08-03 03:49:25,351] [INFO] [config.py:1072:print] quantize_offset .............. 1000
[2022-08-03 03:49:25,351] [INFO] [config.py:1072:print] quantize_period .............. 1000
[2022-08-03 03:49:25,351] [INFO] [config.py:1072:print] quantize_rounding ............ 0
[2022-08-03 03:49:25,351] [INFO] [config.py:1072:print] quantize_start_bits .......... 16
[2022-08-03 03:49:25,351] [INFO] [config.py:1072:print] quantize_target_bits ......... 8
[2022-08-03 03:49:25,351] [INFO] [config.py:1072:print] quantize_training_enabled .... False
[2022-08-03 03:49:25,351] [INFO] [config.py:1072:print] quantize_type ................ 0
[2022-08-03 03:49:25,351] [INFO] [config.py:1072:print] quantize_verbose ............. False
[2022-08-03 03:49:25,351] [INFO] [config.py:1072:print] scheduler_name ............... None
[2022-08-03 03:49:25,351] [INFO] [config.py:1072:print] scheduler_params ............. None
[2022-08-03 03:49:25,351] [INFO] [config.py:1072:print] sparse_attention ............. None
[2022-08-03 03:49:25,351] [INFO] [config.py:1072:print] sparse_gradients_enabled ..... False
[2022-08-03 03:49:25,351] [INFO] [config.py:1072:print] steps_per_print .............. 10
[2022-08-03 03:49:25,351] [INFO] [config.py:1072:print] tensorboard_enabled .......... True
[2022-08-03 03:49:25,351] [INFO] [config.py:1072:print] tensorboard_job_name ......... tensorboard
[2022-08-03 03:49:25,351] [INFO] [config.py:1072:print] tensorboard_output_path ...... ../results/bert_tiny
[2022-08-03 03:49:25,351] [INFO] [config.py:1072:print] train_batch_size ............. 65536
[2022-08-03 03:49:25,351] [INFO] [config.py:1072:print] train_micro_batch_size_per_gpu 64
[2022-08-03 03:49:25,352] [INFO] [config.py:1072:print] use_quantizer_kernel ......... False
[2022-08-03 03:49:25,352] [INFO] [config.py:1072:print] wall_clock_breakdown ......... False
[2022-08-03 03:49:25,352] [INFO] [config.py:1072:print] world_size ................... 1
[2022-08-03 03:49:25,352] [INFO] [config.py:1072:print] zero_allow_comm_data_type_fp32 False
[2022-08-03 03:49:25,352] [INFO] [config.py:1072:print] zero_allow_untested_optimizer False
[2022-08-03 03:49:25,352] [INFO] [config.py:1072:print] zero_config .................. {
"stage": 0,
"contiguous_gradients": true,
"reduce_scatter": true,
"reduce_bucket_size": 5.000000e+08,
"allgather_partitions": true,
"allgather_bucket_size": 5.000000e+08,
"overlap_comm": false,
"load_from_fp32_weights": true,
"elastic_checkpoint": false,
"offload_param": null,
"offload_optimizer": null,
"sub_group_size": 1.000000e+09,
"prefetch_bucket_size": 5.000000e+07,
"param_persistence_threshold": 1.000000e+05,
"max_live_parameters": 1.000000e+09,
"max_reuse_distance": 1.000000e+09,
"gather_16bit_weights_on_model_save": false,
"ignore_unused_parameters": true,
"round_robin_gradients": false,
"legacy_stage1": false
}
[2022-08-03 03:49:25,352] [INFO] [config.py:1072:print] zero_enabled ................. False
[2022-08-03 03:49:25,352] [INFO] [config.py:1072:print] zero_optimization_stage ...... 0
[2022-08-03 03:49:25,352] [INFO] [config.py:1074:print] json = {
"steps_per_print": 10,
"train_batch_size": 6.553600e+04,
"train_micro_batch_size_per_gpu": 64,
"tensorboard": {
"enabled": true,
"output_path": "../results/bert_tiny",
"job_name": "tensorboard"
}
}
Using /root/.cache/torch_extensions/py38_cpu as PyTorch extensions root...
Creating extension directory /root/.cache/torch_extensions/py38_cpu/utils...
Emitting ninja build file /root/.cache/torch_extensions/py38_cpu/utils/build.ninja...
Building extension module utils...
Allowing ninja to set a default number of workers... (overridable by setting the environment variable MAX_JOBS=N)
[1/2] c++ -MMD -MF flatten_unflatten.o.d -DTORCH_EXTENSION_NAME=utils -DTORCH_API_INCLUDE_EXTENSION_H -DPYBIND11_COMPILER_TYPE=\"_gcc\" -DPYBIND11_STDLIB=\"_libstdcpp\" -DPYBIND11_BUILD_ABI=\"_cxxabi1013\" -isystem /usr/local/lib/python3.8/dist-packages/torch/include -isystem /usr/local/lib/python3.8/dist-packages/torch/include/torch/csrc/api/include -isystem /usr/local/lib/python3.8/dist-packages/torch/include/TH -isystem /usr/local/lib/python3.8/dist-packages/torch/include/THC -isystem /usr/include/python3.8 -D_GLIBCXX_USE_CXX11_ABI=1 -fPIC -std=c++14 -c /usr/local/lib/python3.8/dist-packages/deepspeed/ops/csrc/utils/flatten_unflatten.cpp -o flatten_unflatten.o
[2/2] c++ flatten_unflatten.o -shared -L/usr/local/lib/python3.8/dist-packages/torch/lib -lc10 -ltorch_cpu -ltorch -ltorch_python -o utils.so
Loading extension module utils...
Time to load utils op: 10.95207142829895 seconds
Having --resume_from_checkpoint, but no valid checkpoint found. Starting from scratch.
DLL 2022-08-03 03:49:36.619407 - PARAMETER SEED : 12439
DLL 2022-08-03 03:49:36.619553 - PARAMETER train_start : True
DLL 2022-08-03 03:49:36.619584 - PARAMETER batch_size_per_pu : 64
DLL 2022-08-03 03:49:36.619606 - PARAMETER learning_rate : 0.006
Iteration: 0%| | 9/10604 [00:05<1:06:31, 2.65it/s][2022-08-03 03:49:45,064] [INFO] [timer.py:191:stop] 0/10, SamplesPerSec=6195.981015196498, MemAllocated=10.43GB, MaxMemAllocated=10.43GB
Iteration: 0%| | 16/10604 [00:05<31:24, 5.62it/s] [2022-08-03 03:49:45,214] [INFO] [timer.py:191:stop] 0/20, SamplesPerSec=6258.492973855151, MemAllocated=16.07GB, MaxMemAllocated=16.07GB
Iteration: 0%| | 23/10604 [00:05<18:44, 9.41it/s][2022-08-03 03:49:45,358] [INFO] [timer.py:191:stop] 0/30, SamplesPerSec=6272.9609168503475, MemAllocated=21.7GB, MaxMemAllocated=21.7GB
Iteration: 0%| | 38/10604 [00:05<08:37, 20.42it/s][2022-08-03 03:49:45,502] [INFO] [timer.py:191:stop] 0/40, SamplesPerSec=6293.891259734955, MemAllocated=27.33GB, MaxMemAllocated=27.33GB
Iteration: 0%| | 45/10604 [00:06<14:03, 12.51it/s][2022-08-03 03:49:46,542] [INFO] [timer.py:191:stop] 0/50, SamplesPerSec=2219.7888295447615, MemAllocated=11.37GB, MaxMemAllocated=28.27GB
Iteration: 1%| | 54/10604 [00:06<09:35, 18.35it/s][2022-08-03 03:49:46,662] [INFO] [timer.py:191:stop] 0/60, SamplesPerSec=2539.1141652968877, MemAllocated=17.93GB, MaxMemAllocated=28.27GB
Iteration: 1%| | 63/10604 [00:06<06:58, 25.18it/s][2022-08-03 03:49:46,782] [INFO] [timer.py:191:stop] 0/70, SamplesPerSec=2827.424746983928, MemAllocated=24.49GB, MaxMemAllocated=28.27GB
Iteration: 1%| | 72/10604 [00:06<05:21, 32.78it/s][2022-08-03 03:49:47,843] [INFO] [timer.py:191:stop] 0/80, SamplesPerSec=1952.881327148173, MemAllocated=7.61GB, MaxMemAllocated=28.27GB
Iteration: 1%| | 88/10604 [00:08<08:03, 21.75it/s][2022-08-03 03:49:47,975] [INFO] [timer.py:191:stop] 0/90, SamplesPerSec=2134.1209466977493, MemAllocated=13.24GB, MaxMemAllocated=28.27GB
Iteration: 1%| | 96/10604 [00:08<06:20, 27.65it/s][2022-08-03 03:49:48,106] [INFO] [timer.py:191:stop] 0/100, SamplesPerSec=2304.4413089024083, MemAllocated=19.8GB, MaxMemAllocated=28.27GB
Iteration: 1%| | 104/10604 [00:08<05:07, 34.12it/s][2022-08-03 03:49:48,238] [INFO] [timer.py:191:stop] 0/110, SamplesPerSec=2464.3319316012785, MemAllocated=25.43GB, MaxMemAllocated=28.27GB
Iteration: 1%| | 112/10604 [00:08<04:16, 40.83it/s][2022-08-03 03:49:49,290] [INFO] [timer.py:191:stop] 0/120, SamplesPerSec=1982.9642930522155, MemAllocated=9.49GB, MaxMemAllocated=28.27GB
Iteration: 1%| | 128/10604 [00:09<07:28, 23.35it/s][2022-08-03 03:49:49,421] [INFO] [timer.py:191:stop] 0/130, SamplesPerSec=2105.471723195275, MemAllocated=15.12GB, MaxMemAllocated=28.27GB
Iteration: 1%|▏ | 136/10604 [00:09<05:55, 29.48it/s][2022-08-03 03:49:49,552] [INFO] [timer.py:191:stop] 0/140, SamplesPerSec=2223.252612573337, MemAllocated=21.68GB, MaxMemAllocated=28.27GB
Iteration: 1%|▏ | 144/10604 [00:09<04:49, 36.13it/s][2022-08-03 03:49:49,683] [INFO] [timer.py:191:stop] 0/150, SamplesPerSec=2335.5510562711675, MemAllocated=27.3GB, MaxMemAllocated=28.27GB
Iteration: 1%|▏ | 152/10604 [00:10<10:05, 17.26it/s][2022-08-03 03:49:50,738] [INFO] [timer.py:191:stop] 0/160, SamplesPerSec=1997.9735192018434, MemAllocated=11.37GB, MaxMemAllocated=28.27GB
Iteration: 2%|▏ | 168/10604 [00:10<06:06, 28.50it/s][2022-08-03 03:49:50,870] [INFO] [timer.py:191:stop] 0/170, SamplesPerSec=2090.1334709911275, MemAllocated=16.99GB, MaxMemAllocated=28.27GB
Iteration: 2%|▏ | 176/10604 [00:11<04:57, 35.05it/s][2022-08-03 03:49:51,002] [INFO] [timer.py:191:stop] 0/180, SamplesPerSec=2179.430275717034, MemAllocated=23.55GB, MaxMemAllocated=28.27GB
Iteration: 2%|▏ | 183/10604 [00:11<04:33, 38.07it/s][2022-08-03 03:49:51,183] [INFO] [timer.py:191:stop] 0/190, SamplesPerSec=2265.5721113643035, MemAllocated=28.24GB, MaxMemAllocated=28.27GB
Iteration: 2%|▏ | 199/10604 [00:12<07:37, 22.75it/s][2022-08-03 03:49:52,231] [INFO] [timer.py:191:stop] 0/200, SamplesPerSec=2007.4941462053248, MemAllocated=11.37GB, MaxMemAllocated=28.27GB
Iteration: 2%|▏ | 208/10604 [00:12<05:47, 29.92it/s][2022-08-03 03:49:52,351] [INFO] [timer.py:191:stop] 0/210, SamplesPerSec=2083.5534175331413, MemAllocated=17.93GB, MaxMemAllocated=28.27GB
Iteration: 2%|▏ | 217/10604 [00:12<04:36, 37.63it/s][2022-08-03 03:49:52,471] [INFO] [timer.py:191:stop] 0/220, SamplesPerSec=2157.72249654535, MemAllocated=24.49GB, MaxMemAllocated=28.27GB
Iteration: 2%|▏ | 226/10604 [00:12<03:48, 45.51it/s][2022-08-03 03:49:53,524] [INFO] [timer.py:191:stop] 0/230, SamplesPerSec=1951.6916533465012, MemAllocated=8.55GB, MaxMemAllocated=28.27GB
Iteration: 2%|▏ | 234/10604 [00:13<09:03, 19.08it/s
BERT Large Model + DeepSpeed
Next we will run the BERT large model with 340 Million Parameters on a single node using all the 8 HPU’s with DeepSpeed. The configuration for the BERT large are present in bert_large_config.json & deepspeed_config_bert_large.json
# Params: DeepSpeed
NUM_NODES=1
NGPU_PER_NODE=8
- The sharded dataset is specified in the launch script
# Dataset Params
EFS_FOLDER=/mnt/efs
SHARED_FOLDER=${EFS_FOLDER}
data_dir=${SHARED_FOLDER}/hdf5_dataset
# DATA_DIR=${data_dir}/hdf5_lower_case_1_seq_len_128_max_pred_20_masked_lm_prob_0.15_random_seed_12345_dupe_factor_5/wikicorpus_en
DATA_DIR=${data_dir}/hdf5_lower_case_1_seq_len_128_max_pred_20_masked_lm_prob_0.15_random_seed_12345_dupe_factor_5/wikitext-2
The output from the execution is shown below
root@ip-172-31-81-82:/Model-References/PyTorch/nlp/pretraining/deepspeed-bert/scripts# ./run_bert_large.sh
[2022-08-03 03:50:33,383] [WARNING] [runner.py:159:fetch_hostfile] Unable to find hostfile, will proceed with training with local resources only.
Namespace(autotuning='', exclude='', force_multi=False, hostfile='/job/hostfile', include='', launcher='pdsh', launcher_args='', master_addr='172.31.81.82', master_port=29500, module=False, no_local_rank=True, no_python=True, num_gpus=8, num_nodes=1, save_pid=False, use_hpu=False, user_args=['-c', 'source /activate ; cd /Model-References/PyTorch/nlp/pretraining/deepspeed-bert/scripts && python -u ../run_pretraining.py --use_hpu --warmup_proportion=0.2843 --resume_from_checkpoint --do_train --bert_model=bert-base-uncased --config_file=./bert_large_config.json --json-summary=../results/bert_large/dllogger.json --output_dir=../results/bert_large/checkpoints --seed=12439 --optimizer=nvlamb --use_lr_scheduler --input_dir=/mnt/efs/hdf5_dataset/hdf5_lower_case_1_seq_len_128_max_pred_20_masked_lm_prob_0.15_random_seed_12345_dupe_factor_5/wikitext-2 --max_seq_length 128 --max_predictions_per_seq=20 --max_steps=7038 --num_steps_per_checkpoint=200 --learning_rate=0.006 --deepspeed --deepspeed_config=./deepspeed_config_bert_large.json'], user_script='/usr/bin/bash')
[2022-08-03 03:50:33,383] [INFO] [runner.py:466:main] cmd = /usr/bin/python3 -u -m deepspeed.launcher.launch --world_info=eyJsb2NhbGhvc3QiOiBbMCwgMSwgMiwgMywgNCwgNSwgNiwgN119 --master_addr=127.0.0.1 --master_port=29500 --no_python --no_local_rank /usr/bin/bash -c source /activate ; cd /Model-References/PyTorch/nlp/pretraining/deepspeed-bert/scripts && python -u ../run_pretraining.py --use_hpu --warmup_proportion=0.2843 --resume_from_checkpoint --do_train --bert_model=bert-base-uncased --config_file=./bert_large_config.json --json-summary=../results/bert_large/dllogger.json --output_dir=../results/bert_large/checkpoints --seed=12439 --optimizer=nvlamb --use_lr_scheduler --input_dir=/mnt/efs/hdf5_dataset/hdf5_lower_case_1_seq_len_128_max_pred_20_masked_lm_prob_0.15_random_seed_12345_dupe_factor_5/wikitext-2 --max_seq_length 128 --max_predictions_per_seq=20 --max_steps=7038 --num_steps_per_checkpoint=200 --learning_rate=0.006 --deepspeed --deepspeed_config=./deepspeed_config_bert_large.json
[2022-08-03 03:50:33,848] [INFO] [launch.py:104:main] WORLD INFO DICT: {'localhost': [0, 1, 2, 3, 4, 5, 6, 7]}
[2022-08-03 03:50:33,848] [INFO] [launch.py:110:main] nnodes=1, num_local_procs=8, node_rank=0
[2022-08-03 03:50:33,848] [INFO] [launch.py:123:main] global_rank_mapping=defaultdict(<class 'list'>, {'localhost': [0, 1, 2, 3, 4, 5, 6, 7]})
[2022-08-03 03:50:33,848] [INFO] [launch.py:124:main] dist_world_size=8
Distributed training with backend=hccl, device=hpu, local_rank=4
Distributed training with backend=hccl, device=hpu, local_rank=3Distributed training with backend=hccl, device=hpu, local_rank=7Distributed training with backend=hccl, device=hpu, local_rank=0Distributed training with backend=hccl, device=hpu, local_rank=5
Distributed training with backend=hccl, device=hpu, local_rank=2
Distributed training with backend=hccl, device=hpu, local_rank=1
[2022-08-03 03:50:34,535] [INFO] [distributed.py:46:init_distributed] Initializing torch distributed with backend: hccl
Distributed training with backend=hccl, device=hpu, local_rank=6
DLL 2022-08-03 03:50:35.539050 - PARAMETER Config : ["Namespace(bert_model='bert-base-uncased', config_file='./bert_large_config.json', constant_proportion=0.0, deepscale=False, deepscale_config=None, deepspeed=True, deepspeed_config='./deepspeed_config_bert_large.json', deepspeed_mpi=False, disable_progress_bar=False, do_train=True, init_loss_scale=1048576, input_dir='/mnt/efs/hdf5_dataset/hdf5_lower_case_1_seq_len_128_max_pred_20_masked_lm_prob_0.15_random_seed_12345_dupe_factor_5/wikitext-2', json_summary='../results/bert_large/dllogger.json', learning_rate=0.006, local_rank=0, log_bwd_grads=False, log_freq=1.0, log_fwd_activations=False, log_model_inputs=False, loss_scale=0.0, max_predictions_per_seq=20, max_seq_length=128, max_steps=7038.0, no_cuda=False, num_steps_per_checkpoint=200, num_train_epochs=3.0, optimizer='nvlamb', output_dir='../results/bert_large/checkpoints', phase1_end_step=7038, phase2=False, rank=0, resume_from_checkpoint=True, resume_step=-1, scheduler_degree=1.0, seed=12439, skip_checkpoint=False, steps_this_run=7038.0, tensor_logger_max_iterations=0, tensor_logger_path=None, use_env=False, use_hpu=True, use_lazy_mode=True, use_lr_scheduler=True, warmup_proportion=0.2843, world_size=8, zero_optimization=True)"]
Using NVLamb
Using PolyWarmUpScheduler with args={'warmup': 0.2843, 'total_steps': 7038.0, 'degree': 1.0, 'constant': 0.0}
Using NVLamb
Using PolyWarmUpScheduler with args={'warmup': 0.2843, 'total_steps': 7038.0, 'degree': 1.0, 'constant': 0.0}
Using NVLamb
Using PolyWarmUpScheduler with args={'warmup': 0.2843, 'total_steps': 7038.0, 'degree': 1.0, 'constant': 0.0}
Using NVLamb
Using PolyWarmUpScheduler with args={'warmup': 0.2843, 'total_steps': 7038.0, 'degree': 1.0, 'constant': 0.0}
Using NVLamb
Using PolyWarmUpScheduler with args={'warmup': 0.2843, 'total_steps': 7038.0, 'degree': 1.0, 'constant': 0.0}
[2022-08-03 03:50:42,391] [INFO] [logging.py:69:log_dist] [Rank 0] DeepSpeed info: version=0.6.1+0f2b744, git-hash=0f2b744, git-branch=v1.5.0
Using NVLamb
Using PolyWarmUpScheduler with args={'warmup': 0.2843, 'total_steps': 7038.0, 'degree': 1.0, 'constant': 0.0}
Using NVLamb
Using PolyWarmUpScheduler with args={'warmup': 0.2843, 'total_steps': 7038.0, 'degree': 1.0, 'constant': 0.0}
Using NVLamb
Using PolyWarmUpScheduler with args={'warmup': 0.2843, 'total_steps': 7038.0, 'degree': 1.0, 'constant': 0.0}
[2022-08-03 03:50:45,653] [INFO] [engine.py:310:__init__] DeepSpeed Flops Profiler Enabled: False
[2022-08-03 03:50:47,865] [INFO] [stage_1_and_2.py:527:__init__] optimizer state initialized
[2022-08-03 03:50:47,865] [INFO] [logging.py:69:log_dist] [Rank 0] DeepSpeed Final Optimizer = NVLAMB
[2022-08-03 03:50:47,865] [INFO] [engine.py:822:_configure_lr_scheduler] DeepSpeed using client LR scheduler
[2022-08-03 03:50:47,865] [INFO] [logging.py:69:log_dist] [Rank 0] DeepSpeed LR Scheduler = <schedulers.PolyWarmUpScheduler object at 0x7f08c8dc96a0>
[2022-08-03 03:50:47,865] [INFO] [logging.py:69:log_dist] [Rank 0] step=0, skipped=0, lr=[2.9986455118223097e-06, 2.9986455118223097e-06], mom=[(0.9, 0.999), (0.9, 0.999)]
[2022-08-03 03:50:47,866] [INFO] [config.py:1068:print] DeepSpeedEngine configuration:
[2022-08-03 03:50:47,867] [INFO] [config.py:1072:print] activation_checkpointing_config {
"partition_activations": false,
"contiguous_memory_optimization": false,
"cpu_checkpointing": false,
"number_checkpoints": null,
"synchronize_checkpoint_boundary": false,
"profile": false
}
[2022-08-03 03:50:47,867] [INFO] [config.py:1072:print] aio_config ................... {'block_size': 1048576, 'queue_depth': 8, 'thread_count': 1, 'single_submit': False, 'overlap_events': True}
[2022-08-03 03:50:47,867] [INFO] [config.py:1072:print] amp_enabled .................. False
[2022-08-03 03:50:47,867] [INFO] [config.py:1072:print] amp_params ................... False
[2022-08-03 03:50:47,867] [INFO] [config.py:1072:print] autotuning_config ............ {
"enabled": false,
"start_step": null,
"end_step": null,
"metric_path": null,
"arg_mappings": null,
"metric": "throughput",
"model_info": null,
"results_dir": null,
"exps_dir": null,
"overwrite": true,
"fast": true,
"start_profile_step": 3,
"end_profile_step": 5,
"tuner_type": "gridsearch",
"tuner_early_stopping": 5,
"tuner_num_trials": 50,
"model_info_path": null,
"mp_size": 1,
"max_train_batch_size": null,
"min_train_batch_size": 1,
"max_train_micro_batch_size_per_gpu": 1.024000e+03,
"min_train_micro_batch_size_per_gpu": 1,
"num_tuning_micro_batch_sizes": 3
}
[2022-08-03 03:50:47,867] [INFO] [config.py:1072:print] bfloat16_enabled ............. True
[2022-08-03 03:50:47,867] [INFO] [config.py:1072:print] checkpoint_tag_validation_enabled True
[2022-08-03 03:50:47,867] [INFO] [config.py:1072:print] checkpoint_tag_validation_fail False
[2022-08-03 03:50:47,867] [INFO] [config.py:1072:print] communication_data_type ...... None
[2022-08-03 03:50:47,867] [INFO] [config.py:1072:print] curriculum_enabled ........... False
[2022-08-03 03:50:47,867] [INFO] [config.py:1072:print] curriculum_params ............ False
[2022-08-03 03:50:47,867] [INFO] [config.py:1072:print] dataloader_drop_last ......... False
[2022-08-03 03:50:47,867] [INFO] [config.py:1072:print] disable_allgather ............ False
[2022-08-03 03:50:47,867] [INFO] [config.py:1072:print] dump_state ................... False
[2022-08-03 03:50:47,867] [INFO] [config.py:1072:print] dynamic_loss_scale_args ...... None
[2022-08-03 03:50:47,867] [INFO] [config.py:1072:print] eigenvalue_enabled ........... False
[2022-08-03 03:50:47,867] [INFO] [config.py:1072:print] eigenvalue_gas_boundary_resolution 1
[2022-08-03 03:50:47,867] [INFO] [config.py:1072:print] eigenvalue_layer_name ........ bert.encoder.layer
[2022-08-03 03:50:47,867] [INFO] [config.py:1072:print] eigenvalue_layer_num ......... 0
[2022-08-03 03:50:47,867] [INFO] [config.py:1072:print] eigenvalue_max_iter .......... 100
[2022-08-03 03:50:47,867] [INFO] [config.py:1072:print] eigenvalue_stability ......... 1e-06
[2022-08-03 03:50:47,867] [INFO] [config.py:1072:print] eigenvalue_tol ............... 0.01
[2022-08-03 03:50:47,867] [INFO] [config.py:1072:print] eigenvalue_verbose ........... False
[2022-08-03 03:50:47,868] [INFO] [config.py:1072:print] elasticity_enabled ........... False
[2022-08-03 03:50:47,868] [INFO] [config.py:1072:print] flops_profiler_config ........ {
"enabled": false,
"profile_step": 1,
"module_depth": -1,
"top_modules": 1,
"detailed": true,
"output_file": null
}
[2022-08-03 03:50:47,868] [INFO] [config.py:1072:print] fp16_enabled ................. False
[2022-08-03 03:50:47,868] [INFO] [config.py:1072:print] fp16_master_weights_and_gradients False
[2022-08-03 03:50:47,868] [INFO] [config.py:1072:print] fp16_mixed_quantize .......... False
[2022-08-03 03:50:47,868] [INFO] [config.py:1072:print] global_rank .................. 0
[2022-08-03 03:50:47,868] [INFO] [config.py:1072:print] gradient_accumulation_steps .. 256
[2022-08-03 03:50:47,868] [INFO] [config.py:1072:print] gradient_clipping ............ 1.0
[2022-08-03 03:50:47,868] [INFO] [config.py:1072:print] gradient_predivide_factor .... 1.0
[2022-08-03 03:50:47,868] [INFO] [config.py:1072:print] initial_dynamic_scale ........ 1
[2022-08-03 03:50:47,868] [INFO] [config.py:1072:print] loss_scale ................... 1.0
[2022-08-03 03:50:47,868] [INFO] [config.py:1072:print] memory_breakdown ............. False
[2022-08-03 03:50:47,868] [INFO] [config.py:1072:print] optimizer_legacy_fusion ...... False
[2022-08-03 03:50:47,868] [INFO] [config.py:1072:print] optimizer_name ............... None
[2022-08-03 03:50:47,868] [INFO] [config.py:1072:print] optimizer_params ............. None
[2022-08-03 03:50:47,868] [INFO] [config.py:1072:print] pipeline ..................... {'stages': 'auto', 'partition': 'best', 'seed_layers': False, 'activation_checkpoint_interval': 0}
[2022-08-03 03:50:47,868] [INFO] [config.py:1072:print] pld_enabled .................. False
[2022-08-03 03:50:47,868] [INFO] [config.py:1072:print] pld_params ................... False
[2022-08-03 03:50:47,868] [INFO] [config.py:1072:print] prescale_gradients ........... False
[2022-08-03 03:50:47,868] [INFO] [config.py:1072:print] quantize_change_rate ......... 0.001
[2022-08-03 03:50:47,868] [INFO] [config.py:1072:print] quantize_groups .............. 1
[2022-08-03 03:50:47,868] [INFO] [config.py:1072:print] quantize_offset .............. 1000
[2022-08-03 03:50:47,868] [INFO] [config.py:1072:print] quantize_period .............. 1000
[2022-08-03 03:50:47,868] [INFO] [config.py:1072:print] quantize_rounding ............ 0
[2022-08-03 03:50:47,868] [INFO] [config.py:1072:print] quantize_start_bits .......... 16
[2022-08-03 03:50:47,868] [INFO] [config.py:1072:print] quantize_target_bits ......... 8
[2022-08-03 03:50:47,868] [INFO] [config.py:1072:print] quantize_training_enabled .... False
[2022-08-03 03:50:47,868] [INFO] [config.py:1072:print] quantize_type ................ 0
[2022-08-03 03:50:47,868] [INFO] [config.py:1072:print] quantize_verbose ............. False
[2022-08-03 03:50:47,868] [INFO] [config.py:1072:print] scheduler_name ............... None
[2022-08-03 03:50:47,868] [INFO] [config.py:1072:print] scheduler_params ............. None
[2022-08-03 03:50:47,868] [INFO] [config.py:1072:print] sparse_attention ............. None
[2022-08-03 03:50:47,868] [INFO] [config.py:1072:print] sparse_gradients_enabled ..... False
[2022-08-03 03:50:47,868] [INFO] [config.py:1072:print] steps_per_print .............. 10
[2022-08-03 03:50:47,868] [INFO] [config.py:1072:print] tensorboard_enabled .......... False
[2022-08-03 03:50:47,868] [INFO] [config.py:1072:print] tensorboard_job_name ......... DeepSpeedJobName
[2022-08-03 03:50:47,868] [INFO] [config.py:1072:print] tensorboard_output_path ......
[2022-08-03 03:50:47,868] [INFO] [config.py:1072:print] train_batch_size ............. 65536
[2022-08-03 03:50:47,868] [INFO] [config.py:1072:print] train_micro_batch_size_per_gpu 32
[2022-08-03 03:50:47,868] [INFO] [config.py:1072:print] use_quantizer_kernel ......... False
[2022-08-03 03:50:47,868] [INFO] [config.py:1072:print] wall_clock_breakdown ......... False
[2022-08-03 03:50:47,868] [INFO] [config.py:1072:print] world_size ................... 8
[2022-08-03 03:50:47,868] [INFO] [config.py:1072:print] zero_allow_comm_data_type_fp32 False
[2022-08-03 03:50:47,868] [INFO] [config.py:1072:print] zero_allow_untested_optimizer True
[2022-08-03 03:50:47,868] [INFO] [config.py:1072:print] zero_config .................. {
"stage": 1,
"contiguous_gradients": true,
"reduce_scatter": true,
"reduce_bucket_size": 5.000000e+08,
"allgather_partitions": true,
"allgather_bucket_size": 5.000000e+08,
"overlap_comm": false,
"load_from_fp32_weights": true,
"elastic_checkpoint": false,
"offload_param": null,
"offload_optimizer": null,
"sub_group_size": 1.000000e+09,
"prefetch_bucket_size": 5.000000e+07,
"param_persistence_threshold": 1.000000e+05,
"max_live_parameters": 1.000000e+09,
"max_reuse_distance": 1.000000e+09,
"gather_16bit_weights_on_model_save": false,
"ignore_unused_parameters": true,
"round_robin_gradients": false,
"legacy_stage1": false
}
[2022-08-03 03:50:47,868] [INFO] [config.py:1072:print] zero_enabled ................. True
[2022-08-03 03:50:47,868] [INFO] [config.py:1072:print] zero_optimization_stage ...... 1
[2022-08-03 03:50:47,869] [INFO] [config.py:1074:print] json = {
"steps_per_print": 10,
"train_batch_size": 6.553600e+04,
"train_micro_batch_size_per_gpu": 32,
"tensorboard": {
"enabled": false,
"output_path": "../results/bert_large",
"job_name": "tensorboard"
},
"bf16": {
"enabled": true
},
"gradient_clipping": 1.0,
"zero_optimization": {
"stage": 1
},
"zero_allow_untested_optimizer": true
}
Having --resume_from_checkpoint, but no valid checkpoint found. Starting from scratch.
Iteration: 0%| | 8/21208 [00:40<13:58:49, 2.37s/it][2022-08-03 03:51:33,075] [INFO] [timer.py:191:stop] 0/10, SamplesPerSec=2531.6710606279416, MemAllocated=11.29GB, MaxMemAllocated=11.29GB
Iteration: 0%| | 18/21208 [00:41<2:22:05, 2.49it/s][2022-08-03 03:51:34,145] [INFO] [timer.py:191:stop] 0/20, SamplesPerSec=2497.4441085778476, MemAllocated=12.31GB, MaxMemAllocated=12.57GB
Iteration: 0%| | 29/21208 [00:42<47:13, 7.47it/s][2022-08-03 03:51:35,200] [INFO] [timer.py:191:stop] 0/30, SamplesPerSec=2503.430727258617, MemAllocated=13.6GB, MaxMemAllocated=13.6GB
Iteration: 0%| | 39/21208 [00:43<38:16, 9.22it/s][2022-08-03 03:51:36,238] [INFO] [timer.py:191:stop] 0/40, SamplesPerSec=2515.727807677503, MemAllocated=14.9GB, MaxMemAllocated=14.9GB
Iteration: 0%| | 48/21208 [00:44<37:03, 9.51it/s][2022-08-03 03:51:37,333] [INFO] [timer.py:191:stop] 0/50, SamplesPerSec=2493.433523873937, MemAllocated=16.2GB, MaxMemAllocated=16.2GB
BERT 1.5B Model + DeepSpeed
Next we will run the BERT 1.5B model with 1.5 Billion Parameters on a single node using all the 8 HPU’s with DeepSpeed. The configuration for the BERT large are present in bert_1.5b_config.json & deepspeed_config_bert_1.5b.json. Without deepspeed, it is not possible to train such a big model on 1 node with 32GB of HPU memory. This clearly shows the ability of the HPU to utilize deepspeed functionality to train large models.
# Params: DeepSpeed
NUM_NODES=1
NGPU_PER_NODE=8
- The sharded dataset is specified in the launch script
# Dataset Params
EFS_FOLDER=/mnt/efs
SHARED_FOLDER=${EFS_FOLDER}
data_dir=${SHARED_FOLDER}/hdf5_dataset
# DATA_DIR=${data_dir}/hdf5_lower_case_1_seq_len_128_max_pred_20_masked_lm_prob_0.15_random_seed_12345_dupe_factor_5/wikicorpus_en
DATA_DIR=${data_dir}/hdf5_lower_case_1_seq_len_128_max_pred_20_masked_lm_prob_0.15_random_seed_12345_dupe_factor_5/wikitext-2
root@ip-172-31-81-82:/Model-References/PyTorch/nlp/pretraining/deepspeed-bert/scripts# ./run_bert_1.5b.sh
[2022-08-03 03:53:01,784] [WARNING] [runner.py:159:fetch_hostfile] Unable to find hostfile, will proceed with training with local resources only.
Namespace(autotuning='', exclude='', force_multi=False, hostfile='/job/hostfile', include='', launcher='pdsh', launcher_args='', master_addr='172.31.81.82', master_port=29500, module=False, no_local_rank=True, no_python=True, num_gpus=8, num_nodes=1, save_pid=False, use_hpu=False, user_args=['-c', 'source /activate ; cd /Model-References/PyTorch/nlp/pretraining/deepspeed-bert/scripts && python -u ../run_pretraining.py --use_hpu --warmup_proportion=0.05 --constant_proportion=0.25 --resume_from_checkpoint --do_train --bert_model=bert-base-uncased --config_file=./bert_1.5b_config.json --json-summary=../results/bert_1.5b/dllogger.json --output_dir=../results/bert_1.5b/checkpoints --seed=12439 --optimizer=nvlamb --use_lr_scheduler --input_dir=/mnt/efs/hdf5_dataset/hdf5_lower_case_1_seq_len_128_max_pred_20_masked_lm_prob_0.15_random_seed_12345_dupe_factor_5/wikitext-2 --max_seq_length 128 --max_predictions_per_seq=20 --max_steps=155000 --num_steps_per_checkpoint=1000000 --learning_rate=0.0015 --deepspeed --deepspeed_config=./deepspeed_config_bert_1.5b.json'], user_script='/usr/bin/bash')
[2022-08-03 03:53:01,784] [INFO] [runner.py:466:main] cmd = /usr/bin/python3 -u -m deepspeed.launcher.launch --world_info=eyJsb2NhbGhvc3QiOiBbMCwgMSwgMiwgMywgNCwgNSwgNiwgN119 --master_addr=127.0.0.1 --master_port=29500 --no_python --no_local_rank /usr/bin/bash -c source /activate ; cd /Model-References/PyTorch/nlp/pretraining/deepspeed-bert/scripts && python -u ../run_pretraining.py --use_hpu --warmup_proportion=0.05 --constant_proportion=0.25 --resume_from_checkpoint --do_train --bert_model=bert-base-uncased --config_file=./bert_1.5b_config.json --json-summary=../results/bert_1.5b/dllogger.json --output_dir=../results/bert_1.5b/checkpoints --seed=12439 --optimizer=nvlamb --use_lr_scheduler --input_dir=/mnt/efs/hdf5_dataset/hdf5_lower_case_1_seq_len_128_max_pred_20_masked_lm_prob_0.15_random_seed_12345_dupe_factor_5/wikitext-2 --max_seq_length 128 --max_predictions_per_seq=20 --max_steps=155000 --num_steps_per_checkpoint=1000000 --learning_rate=0.0015 --deepspeed --deepspeed_config=./deepspeed_config_bert_1.5b.json
[2022-08-03 03:53:02,252] [INFO] [launch.py:104:main] WORLD INFO DICT: {'localhost': [0, 1, 2, 3, 4, 5, 6, 7]}
[2022-08-03 03:53:02,252] [INFO] [launch.py:110:main] nnodes=1, num_local_procs=8, node_rank=0
[2022-08-03 03:53:02,252] [INFO] [launch.py:123:main] global_rank_mapping=defaultdict(<class 'list'>, {'localhost': [0, 1, 2, 3, 4, 5, 6, 7]})
[2022-08-03 03:53:02,252] [INFO] [launch.py:124:main] dist_world_size=8
Distributed training with backend=hccl, device=hpu, local_rank=2
Distributed training with backend=hccl, device=hpu, local_rank=4
Distributed training with backend=hccl, device=hpu, local_rank=7Distributed training with backend=hccl, device=hpu, local_rank=5
Distributed training with backend=hccl, device=hpu, local_rank=0
Distributed training with backend=hccl, device=hpu, local_rank=1
[2022-08-03 03:53:02,972] [INFO] [distributed.py:46:init_distributed] Initializing torch distributed with backend: hccl
Distributed training with backend=hccl, device=hpu, local_rank=6
Distributed training with backend=hccl, device=hpu, local_rank=3
DLL 2022-08-03 03:53:03.981529 - PARAMETER Config : ["Namespace(bert_model='bert-base-uncased', config_file='./bert_1.5b_config.json', constant_proportion=0.25, deepscale=False, deepscale_config=None, deepspeed=True, deepspeed_config='./deepspeed_config_bert_1.5b.json', deepspeed_mpi=False, disable_progress_bar=False, do_train=True, init_loss_scale=1048576, input_dir='/mnt/efs/hdf5_dataset/hdf5_lower_case_1_seq_len_128_max_pred_20_masked_lm_prob_0.15_random_seed_12345_dupe_factor_5/wikitext-2', json_summary='../results/bert_1.5b/dllogger.json', learning_rate=0.0015, local_rank=0, log_bwd_grads=False, log_freq=1.0, log_fwd_activations=False, log_model_inputs=False, loss_scale=0.0, max_predictions_per_seq=20, max_seq_length=128, max_steps=155000.0, no_cuda=False, num_steps_per_checkpoint=1000000, num_train_epochs=3.0, optimizer='nvlamb', output_dir='../results/bert_1.5b/checkpoints', phase1_end_step=7038, phase2=False, rank=0, resume_from_checkpoint=True, resume_step=-1, scheduler_degree=1.0, seed=12439, skip_checkpoint=False, steps_this_run=155000.0, tensor_logger_max_iterations=0, tensor_logger_path=None, use_env=False, use_hpu=True, use_lazy_mode=True, use_lr_scheduler=True, warmup_proportion=0.05, world_size=8, zero_optimization=True)"]
Using NVLamb
Using PolyWarmUpScheduler with args={'warmup': 0.05, 'total_steps': 155000.0, 'degree': 1.0, 'constant': 0.25}
Using NVLamb
Using PolyWarmUpScheduler with args={'warmup': 0.05, 'total_steps': 155000.0, 'degree': 1.0, 'constant': 0.25}
Using NVLamb
Using PolyWarmUpScheduler with args={'warmup': 0.05, 'total_steps': 155000.0, 'degree': 1.0, 'constant': 0.25}
Using NVLamb
Using PolyWarmUpScheduler with args={'warmup': 0.05, 'total_steps': 155000.0, 'degree': 1.0, 'constant': 0.25}
[2022-08-03 03:53:29,576] [INFO] [logging.py:69:log_dist] [Rank 0] DeepSpeed info: version=0.6.1+0f2b744, git-hash=0f2b744, git-branch=v1.5.0
Using NVLamb
Using PolyWarmUpScheduler with args={'warmup': 0.05, 'total_steps': 155000.0, 'degree': 1.0, 'constant': 0.25}
Using NVLamb
Using PolyWarmUpScheduler with args={'warmup': 0.05, 'total_steps': 155000.0, 'degree': 1.0, 'constant': 0.25}
Using NVLamb
Using PolyWarmUpScheduler with args={'warmup': 0.05, 'total_steps': 155000.0, 'degree': 1.0, 'constant': 0.25}
Using NVLamb
Using PolyWarmUpScheduler with args={'warmup': 0.05, 'total_steps': 155000.0, 'degree': 1.0, 'constant': 0.25}
[2022-08-03 03:53:42,330] [INFO] [engine.py:822:_configure_lr_scheduler] DeepSpeed using client LR scheduler
[2022-08-03 03:53:42,330] [INFO] [logging.py:69:log_dist] [Rank 0] DeepSpeed LR Scheduler = <schedulers.PolyWarmUpScheduler object at 0x7f1e42cf5d60>
[2022-08-03 03:53:42,330] [INFO] [logging.py:69:log_dist] [Rank 0] step=0, skipped=0, lr=[1.935483870967742e-07, 1.935483870967742e-07], mom=[(0.9, 0.999), (0.9, 0.999)]
[2022-08-03 03:53:42,332] [INFO] [config.py:1068:print] DeepSpeedEngine configuration:
[2022-08-03 03:53:42,332] [INFO] [config.py:1072:print] activation_checkpointing_config {
"partition_activations": false,
"contiguous_memory_optimization": false,
"cpu_checkpointing": false,
"number_checkpoints": null,
"synchronize_checkpoint_boundary": false,
"profile": false
}
[2022-08-03 03:53:42,332] [INFO] [config.py:1072:print] aio_config ................... {'block_size': 1048576, 'queue_depth': 8, 'thread_count': 1, 'single_submit': False, 'overlap_events': True}
[2022-08-03 03:53:42,332] [INFO] [config.py:1072:print] amp_enabled .................. False
[2022-08-03 03:53:42,332] [INFO] [config.py:1072:print] amp_params ................... False
[2022-08-03 03:53:42,333] [INFO] [config.py:1072:print] autotuning_config ............ {
"enabled": false,
"start_step": null,
"end_step": null,
"metric_path": null,
"arg_mappings": null,
"metric": "throughput",
"model_info": null,
"results_dir": null,
"exps_dir": null,
"overwrite": true,
"fast": true,
"start_profile_step": 3,
"end_profile_step": 5,
"tuner_type": "gridsearch",
"tuner_early_stopping": 5,
"tuner_num_trials": 50,
"model_info_path": null,
"mp_size": 1,
"max_train_batch_size": null,
"min_train_batch_size": 1,
"max_train_micro_batch_size_per_gpu": 1.024000e+03,
"min_train_micro_batch_size_per_gpu": 1,
"num_tuning_micro_batch_sizes": 3
}
[2022-08-03 03:53:42,333] [INFO] [config.py:1072:print] bfloat16_enabled ............. True
[2022-08-03 03:53:42,333] [INFO] [config.py:1072:print] checkpoint_tag_validation_enabled True
[2022-08-03 03:53:42,333] [INFO] [config.py:1072:print] checkpoint_tag_validation_fail False
[2022-08-03 03:53:42,333] [INFO] [config.py:1072:print] communication_data_type ...... None
[2022-08-03 03:53:42,333] [INFO] [config.py:1072:print] curriculum_enabled ........... False
[2022-08-03 03:53:42,333] [INFO] [config.py:1072:print] curriculum_params ............ False
[2022-08-03 03:53:42,333] [INFO] [config.py:1072:print] dataloader_drop_last ......... False
[2022-08-03 03:53:42,333] [INFO] [config.py:1072:print] disable_allgather ............ False
[2022-08-03 03:53:42,333] [INFO] [config.py:1072:print] dump_state ................... False
[2022-08-03 03:53:42,333] [INFO] [config.py:1072:print] dynamic_loss_scale_args ...... None
[2022-08-03 03:53:42,333] [INFO] [config.py:1072:print] eigenvalue_enabled ........... False
[2022-08-03 03:53:42,333] [INFO] [config.py:1072:print] eigenvalue_gas_boundary_resolution 1
[2022-08-03 03:53:42,333] [INFO] [config.py:1072:print] eigenvalue_layer_name ........ bert.encoder.layer
[2022-08-03 03:53:42,333] [INFO] [config.py:1072:print] eigenvalue_layer_num ......... 0
[2022-08-03 03:53:42,333] [INFO] [config.py:1072:print] eigenvalue_max_iter .......... 100
[2022-08-03 03:53:42,333] [INFO] [config.py:1072:print] eigenvalue_stability ......... 1e-06
[2022-08-03 03:53:42,333] [INFO] [config.py:1072:print] eigenvalue_tol ............... 0.01
[2022-08-03 03:53:42,333] [INFO] [config.py:1072:print] eigenvalue_verbose ........... False
[2022-08-03 03:53:42,333] [INFO] [config.py:1072:print] elasticity_enabled ........... False
[2022-08-03 03:53:42,333] [INFO] [config.py:1072:print] flops_profiler_config ........ {
"enabled": false,
"profile_step": 1,
"module_depth": -1,
"top_modules": 1,
"detailed": true,
"output_file": null
}
[2022-08-03 03:53:42,333] [INFO] [config.py:1072:print] fp16_enabled ................. False
[2022-08-03 03:53:42,333] [INFO] [config.py:1072:print] fp16_master_weights_and_gradients False
[2022-08-03 03:53:42,333] [INFO] [config.py:1072:print] fp16_mixed_quantize .......... False
[2022-08-03 03:53:42,333] [INFO] [config.py:1072:print] global_rank .................. 0
[2022-08-03 03:53:42,333] [INFO] [config.py:1072:print] gradient_accumulation_steps .. 192
[2022-08-03 03:53:42,333] [INFO] [config.py:1072:print] gradient_clipping ............ 1.0
[2022-08-03 03:53:42,333] [INFO] [config.py:1072:print] gradient_predivide_factor .... 1.0
[2022-08-03 03:53:42,333] [INFO] [config.py:1072:print] initial_dynamic_scale ........ 1
[2022-08-03 03:53:42,333] [INFO] [config.py:1072:print] loss_scale ................... 1.0
[2022-08-03 03:53:42,333] [INFO] [config.py:1072:print] memory_breakdown ............. False
[2022-08-03 03:53:42,333] [INFO] [config.py:1072:print] optimizer_legacy_fusion ...... False
[2022-08-03 03:53:42,333] [INFO] [config.py:1072:print] optimizer_name ............... None
[2022-08-03 03:53:42,333] [INFO] [config.py:1072:print] optimizer_params ............. None
[2022-08-03 03:53:42,333] [INFO] [config.py:1072:print] pipeline ..................... {'stages': 'auto', 'partition': 'best', 'seed_layers': False, 'activation_checkpoint_interval': 0}
[2022-08-03 03:53:42,333] [INFO] [config.py:1072:print] pld_enabled .................. False
[2022-08-03 03:53:42,333] [INFO] [config.py:1072:print] pld_params ................... False
[2022-08-03 03:53:42,333] [INFO] [config.py:1072:print] prescale_gradients ........... False
[2022-08-03 03:53:42,333] [INFO] [config.py:1072:print] quantize_change_rate ......... 0.001
[2022-08-03 03:53:42,333] [INFO] [config.py:1072:print] quantize_groups .............. 1
[2022-08-03 03:53:42,333] [INFO] [config.py:1072:print] quantize_offset .............. 1000
[2022-08-03 03:53:42,333] [INFO] [config.py:1072:print] quantize_period .............. 1000
[2022-08-03 03:53:42,333] [INFO] [config.py:1072:print] quantize_rounding ............ 0
[2022-08-03 03:53:42,334] [INFO] [config.py:1072:print] quantize_start_bits .......... 16
[2022-08-03 03:53:42,334] [INFO] [config.py:1072:print] quantize_target_bits ......... 8
[2022-08-03 03:53:42,334] [INFO] [config.py:1072:print] quantize_training_enabled .... False
[2022-08-03 03:53:42,334] [INFO] [config.py:1072:print] quantize_type ................ 0
[2022-08-03 03:53:42,334] [INFO] [config.py:1072:print] quantize_verbose ............. False
[2022-08-03 03:53:42,334] [INFO] [config.py:1072:print] scheduler_name ............... None
[2022-08-03 03:53:42,334] [INFO] [config.py:1072:print] scheduler_params ............. None
[2022-08-03 03:53:42,334] [INFO] [config.py:1072:print] sparse_attention ............. None
[2022-08-03 03:53:42,334] [INFO] [config.py:1072:print] sparse_gradients_enabled ..... False
[2022-08-03 03:53:42,334] [INFO] [config.py:1072:print] steps_per_print .............. 1
[2022-08-03 03:53:42,334] [INFO] [config.py:1072:print] tensorboard_enabled .......... False
[2022-08-03 03:53:42,334] [INFO] [config.py:1072:print] tensorboard_job_name ......... DeepSpeedJobName
[2022-08-03 03:53:42,334] [INFO] [config.py:1072:print] tensorboard_output_path ......
[2022-08-03 03:53:42,334] [INFO] [config.py:1072:print] train_batch_size ............. 12288
[2022-08-03 03:53:42,334] [INFO] [config.py:1072:print] train_micro_batch_size_per_gpu 8
[2022-08-03 03:53:42,334] [INFO] [config.py:1072:print] use_quantizer_kernel ......... False
[2022-08-03 03:53:42,334] [INFO] [config.py:1072:print] wall_clock_breakdown ......... False
[2022-08-03 03:53:42,334] [INFO] [config.py:1072:print] world_size ................... 8
[2022-08-03 03:53:42,334] [INFO] [config.py:1072:print] zero_allow_comm_data_type_fp32 False
[2022-08-03 03:53:42,334] [INFO] [config.py:1072:print] zero_allow_untested_optimizer True
[2022-08-03 03:53:42,334] [INFO] [config.py:1072:print] zero_config .................. {
"stage": 1,
"contiguous_gradients": true,
"reduce_scatter": true,
"reduce_bucket_size": 5.000000e+08,
"allgather_partitions": true,
"allgather_bucket_size": 5.000000e+08,
"overlap_comm": false,
"load_from_fp32_weights": true,
"elastic_checkpoint": false,
"offload_param": null,
"offload_optimizer": null,
"sub_group_size": 1.000000e+09,
"prefetch_bucket_size": 5.000000e+07,
"param_persistence_threshold": 1.000000e+05,
"max_live_parameters": 1.000000e+09,
"max_reuse_distance": 1.000000e+09,
"gather_16bit_weights_on_model_save": false,
"ignore_unused_parameters": true,
"round_robin_gradients": false,
"legacy_stage1": false
}
[2022-08-03 03:53:42,334] [INFO] [config.py:1072:print] zero_enabled ................. True
[2022-08-03 03:53:42,334] [INFO] [config.py:1072:print] zero_optimization_stage ...... 1
[2022-08-03 03:53:42,334] [INFO] [config.py:1074:print] json = {
"steps_per_print": 1,
"train_batch_size": 1.228800e+04,
"train_micro_batch_size_per_gpu": 8,
"tensorboard": {
"enabled": false,
"output_path": "../results/bert_1.5b",
"job_name": "tensorboard"
},
"bf16": {
"enabled": true
},
"gradient_clipping": 1.0,
"zero_optimization": {
"stage": 1
},
"zero_allow_untested_optimizer": true
}
Having --resume_from_checkpoint, but no valid checkpoint found. Starting from scratch.
Iteration: 0%| | 2/84829 [01:16<911:00:00, 38.66s/it][2022-08-03 03:55:04,854] [INFO] [timer.py:191:stop] 0/3, SamplesPerSec=385.6216264360138, MemAllocated=15.63GB, MaxMemAllocated=16.35GB
Iteration: 0%| | 3/84829 [01:17<496:50:19, 21.09s/it][2022-08-03 03:55:05,076] [INFO] [timer.py:191:stop] 0/4, SamplesPerSec=332.5694859481934, MemAllocated=15.63GB, MaxMemAllocated=16.35GB
Iteration: 0%| | 4/84829 [01:17<302:45:34, 12.85s/it][2022-08-03 03:55:05,254] [INFO] [timer.py:191:stop] 0/5, SamplesPerSec=343.4840980446769, MemAllocated=15.7GB, MaxMemAllocated=16.35GB
Iteration: 0%| | 5/84829 [01:17<195:05:23, 8.28s/it][2022-08-03 03:55:05,432] [INFO] [timer.py:191:stop] 0/6, SamplesPerSec=349.4341073717083, MemAllocated=15.7GB, MaxMemAllocated=16.35GB
Iteration: 0%| | 6/84829 [01:17<130:10:43, 5.52s/it][2022-08-03 03:55:05,610] [INFO] [timer.py:191:stop] 0/7, SamplesPerSec=352.7753682822188, MemAllocated=15.7GB, MaxMemAllocated=16.35GB
Iteration: 0%| | 7/84829 [01:17<88:59:25, 3.78s/it] [2022-08-03 03:55:05,784] [INFO] [timer.py:191:stop] 0/8, SamplesPerSec=356.11232949040476, MemAllocated=15.7GB, MaxMemAllocated=16.35GB
Iteration: 0%| | 8/84829 [01:17<61:58:12, 2.63s/it][2022-08-03 03:55:06,006] [INFO] [timer.py:191:stop] 0/9, SamplesPerSec=345.4320661565408, MemAllocated=15.7GB, MaxMemAllocated=16.35GB
Iteration: 0%| | 9/84829 [01:18<44:14:02, 1.88s/it][2022-08-03 03:55:06,179] [INFO] [timer.py:191:stop] 0/10, SamplesPerSec=349.29599413405975, MemAllocated=15.7GB, MaxMemAllocated=16.35GB
Iteration: 0%| | 10/84829 [01:18<31:49:51, 1.35s/it][2022-08-03 03:55:06,351] [INFO] [timer.py:191:stop] 0/11, SamplesPerSec=352.334117264104, MemAllocated=15.77GB, MaxMemAllocated=16.35GB
Iteration: 0%| | 11/84829 [01:18<23:19:55, 1.01it/s][2022-08-03 03:55:06,525] [INFO] [timer.py:191:stop] 0/12, SamplesPerSec=354.54060565076816, MemAllocated=15.77GB, MaxMemAllocated=16.35GB
Iteration: 0%| | 12/84829 [01:18<17:28:42, 1.35it/s][2022-08-03 03:55:06,698] [INFO] [timer.py:191:stop] 0/13, SamplesPerSec=356.5436468592767, MemAllocated=15.77GB, MaxMemAllocated=16.35GB
Iteration: 0%| | 13/84829 [01:18<13:24:59, 1.76it/s][2022-08-03 03:55:06,871] [INFO] [timer.py:191:stop] 0/14, SamplesPerSec=358.11683441540936, MemAllocated=15.78GB, MaxMemAllocated=16.35GB
Iteration: 0%| | 14/84829 [01:19<10:35:52, 2.22it/s][2022-08-03 03:55:07,089] [INFO] [timer.py:191:stop] 0/15, SamplesPerSec=352.72565446063413, MemAllocated=15.77GB, MaxMemAllocated=16.35GB
Iteration: 0%| | 15/84829 [01:19<8:56:58, 2.63it/s] [2022-08-03 03:55:07,314] [INFO] [timer.py:191:stop] 0/16, SamplesPerSec=347.17486392812646, MemAllocated=15.77GB, MaxMemAllocated=16.35GB
Iteration: 0%| | 16/84829 [01:19<7:51:18, 3.00it/s][2022-08-03 03:55:07,489] [INFO] [timer.py:191:stop] 0/17, SamplesPerSec=348.8291889709685, MemAllocated=15.85GB, MaxMemAllocated=16.35GB
Iteration: 0%| | 17/84829 [01:19<6:43:50, 3.50it/s][2022-08-03 03:55:07,666] [INFO] [timer.py:191:stop] 0/18, SamplesPerSec=350.0179163270706, MemAllocated=15.84GB, MaxMemAllocated=16.35GB
Iteration: 0%| | 18/84829 [01:19<5:57:37, 3.95it/s][2022-08-03 03:55:07,841] [INFO] [timer.py:191:stop] 0/19, SamplesPerSec=351.2868528622887, MemAllocated=15.84GB, MaxMemAllocated=16.35GB
Iteration: 0%| | 19/84829 [01:19<5:24:29, 4.36it/s][2022-08-03 03:55:08,017] [INFO] [timer.py:191:stop] 0/20, SamplesPerSec=352.28363982137046, MemAllocated=15.84GB, MaxMemAllocated=16.35GB
Iteration: 0%| | 20/84829 [01:20<5:01:53, 4.68it/s][2022-08-03 03:55:08,194] [INFO] [timer.py:191:stop] 0/21, SamplesPerSec=353.1591796206235, MemAllocated=15.84GB, MaxMemAllocated=16.35GB
Iteration: 0%| | 21/84829 [01:20<4:46:09, 4.94it/s][2022-08-03 03:55:08,416] [INFO] [timer.py:191:stop] 0/22, SamplesPerSec=349.5718974024795, MemAllocated=15.84GB, MaxMemAllocated=16.35GB
Iteration: 0%| | 22/84829 [01:20<4:54:26, 4.80it/s][2022-08-03 03:55:08,595] [INFO] [timer.py:191:stop] 0/23, SamplesPerSec=350.2261983228466, MemAllocated=15.91GB, MaxMemAllocated=16.35GB
Iteration: 0%| | 23/84829 [01:20<4:42:11, 5.01it/s][2022-08-03 03:55:08,776] [INFO] [timer.py:191:stop] 0/24, SamplesPerSec=350.7037485746822, MemAllocated=15.91GB, MaxMemAllocated=16.35GB
Iteration: 0%| | 24/84829 [01:20<4:34:10, 5.16it/s][2022-08-03 03:55:08,951] [INFO] [timer.py:191:stop] 0/25, SamplesPerSec=351.6419334972389, MemAllocated=15.91GB, MaxMemAllocated=16.35GB
Iteration: 0%| | 25/84829 [01:21<4:26:01, 5.31it/s][2022-08-03 03:55:09,128] [INFO] [timer.py:191:stop] 0/26, SamplesPerSec=352.31816970998784, MemAllocated=15.91GB, MaxMemAllocated=16.35GB
Iteration: 0%| | 26/84829 [01:21<4:21:20, 5.41it/s][2022-08-03 03:55:09,301] [INFO] [timer.py:191:stop] 0/27, SamplesPerSec=353.220442288324, MemAllocated=15.91GB, MaxMemAllocated=16.35GB
Iteration: 0%| | 27/84829 [01:21<4:16:30, 5.51it/s][2022-08-03 03:55:09,526] [INFO] [timer.py:191:stop] 0/28, SamplesPerSec=350.2575449067028, MemAllocated=15.91GB, MaxMemAllocated=16.35GB
Iteration: 0%| | 28/84829 [01:21<4:34:50, 5.14it/s][2022-08-03 03:55:09,699] [INFO] [timer.py:191:stop] 0/29, SamplesPerSec=351.19348545281997, MemAllocated=15.98GB, MaxMemAllocated=16.35GB
Iteration: 0%| | 29/84829 [01:21<4:25:49, 5.32it/s][2022-08-03 03:55:09,876] [INFO] [timer.py:191:stop] 0/30, SamplesPerSec=351.8298976967061, MemAllocated=15.98GB, MaxMemAllocated=16.35GB
Iteration: 0%| | 30/84829 [01:22<4:20:53, 5.42it/s][2022-08-03 03:55:10,045] [INFO] [timer.py:191:stop] 0/31, SamplesPerSec=352.90947405680953, MemAllocated=15.98GB, MaxMemAllocated=16.35GB
Iteration: 0%| | 31/84829 [01:22<4:14:20, 5.56it/s][2022-08-03 03:55:10,223] [INFO] [timer.py:191:stop] 0/32, SamplesPerSec=353.37498880490733, MemAllocated=15.98GB, MaxMemAllocated=16.35GB
Iteration: 0%| | 32/84829 [01:22<4:13:21, 5.58it/s][2022-08-03 03:55:10,485] [INFO] [timer.py:191:stop] 0/33, SamplesPerSec=348.5676361398347, MemAllocated=15.98GB, MaxMemAllocated=16.35GB
Iteration: 0%| | 33/84829 [01:22<4:48:58, 4.89it/s][2022-08-03 03:55:10,683] [INFO] [timer.py:191:stop] 0/34, SamplesPerSec=347.9777273113958, MemAllocated=15.98GB, MaxMemAllocated=16.35GB
Iteration: 0%| | 34/84829 [01:22<4:46:08, 4.94it/s][2022-08-03 03:55:10,877] [INFO] [timer.py:191:stop] 0/35, SamplesPerSec=347.6590664327215, MemAllocated=15.98GB, MaxMemAllocated=16.35GB
Iteration: 0%| | 35/84829 [01:23<4:42:13, 5.01it/s][2022-08-03 03:55:11,048] [INFO] [timer.py:191:stop] 0/36, SamplesPerSec=348.568119250647, MemAllocated=15.98GB, MaxMemAllocated=16.35GB
Iteration: 0%| | 36/84829 [01:23<4:30:10, 5.23it/s][2022-08-03 03:55:11,220] [INFO] [timer.py:191:stop] 0/37, SamplesPerSec=349.38885331250816, MemAllocated=16.05GB, MaxMemAllocated=16.35GB
Iteration: 0%| | 37/84829 [01:23<4:22:00, 5.39it/s][2022-08-03 03:55:11,453] [INFO] [timer.py:191:stop] 0/38, SamplesPerSec=346.97607321670085, MemAllocated=16.05GB, MaxMemAllocated=16.35GB
Iteration: 0%| | 38/84829 [01:23<4:41:59, 5.01it/s][2022-08-03 03:55:11,630] [INFO] [timer.py:191:stop] 0/39, SamplesPerSec=347.5232224039246, MemAllocated=16.05GB, MaxMemAllocated=16.35GB
Iteration: 0%| | 39/84829 [01:23<4:32:30, 5.19it/s][2022-08-03 03:55:11,807] [INFO] [timer.py:191:stop] 0/40, SamplesPerSec=348.0647589555669, MemAllocated=16.05GB, MaxMemAllocated=16.35GB
Iteration: 0%| | 40/84829 [01:23<4:25:40, 5.32it/s][2022-08-03 03:55:11,984] [INFO] [timer.py:191:stop] 0/41, SamplesPerSec=348.55246558908544, MemAllocated=16.05GB, MaxMemAllocated=16.35GB
Iteration: 0%| | 41/84829 [01:24<4:21:07, 5.41it/s][2022-08-03 03:55:12,209] [INFO] [timer.py:191:stop] 0/42, SamplesPerSec=346.74044993641724, MemAllocated=16.05GB, MaxMemAllocated=16.35GB
Iteration: 0%| | 42/84829 [01:24<4:38:25, 5.08it/s][2022-08-03 03:55:12,383] [INFO] [timer.py:191:stop] 0/43, SamplesPerSec=347.3996069654326, MemAllocated=16.05GB, MaxMemAllocated=16.35GB
Iteration: 0%| | 43/84829 [01:24<4:28:34, 5.26it/s][2022-08-03 03:55:12,554] [INFO] [timer.py:191:stop] 0/44, SamplesPerSec=348.1541633046956, MemAllocated=16.12GB, MaxMemAllocated=16.35GB
Iteration: 0%| | 44/84829 [01:24<4:20:28, 5.43it/s][2022-08-03 03:55:12,724] [INFO] [timer.py:191:stop] 0/45, SamplesPerSec=348.92420404357875, MemAllocated=16.12GB, MaxMemAllocated=16.35GB
Multi Node Training
The multinode training can be invoked by just modifying the number of nodes in the launch script
# Params: DeepSpeed
NUM_NODES=2
NGPU_PER_NODE=8
- The sharded dataset is specified in the launch script
# Dataset Params
EFS_FOLDER=/mnt/efs
SHARED_FOLDER=${EFS_FOLDER}
data_dir=${SHARED_FOLDER}/hdf5_dataset
# DATA_DIR=${data_dir}/hdf5_lower_case_1_seq_len_128_max_pred_20_masked_lm_prob_0.15_random_seed_12345_dupe_factor_5/wikicorpus_en
DATA_DIR=${data_dir}/hdf5_lower_case_1_seq_len_128_max_pred_20_masked_lm_prob_0.15_random_seed_12345_dupe_factor_5/wikitext-2
The hostfile is already assembled in the master node in /tmp/hostfile
root@ip-172-31-81-82:/Model-References/PyTorch/nlp/pretraining/deepspeed-bert/scripts# cat /tmp/hostfile
172.31.81.82 slots=8
172.31.94.102 slots=8
This will automatically include the HOSTFILE and pass it as an argument to the deepspeed for the job
#Configure multinode
if [ "$NUM_NODES" -ne "1" -a -f "$HOSTSFILE" ]
then
MULTINODE_CMD="--hostfile=$HOSTSFILE"
fi
mkdir -p $RESULTS_DIR
deepspeed --num_nodes ${NUM_NODES} \
--num_gpus ${NGPU_PER_NODE} \
--master_addr ${MULTI_HLS_IPS} \
--no_local_rank \
--no_python \
$MULTINODE_CMD \
/usr/bin/bash -c "$CMD" 2>&1 | tee $RESULTS_DIR/train_log.txt
The output from the multi node run is shown below
root@ip-172-31-81-82:/Model-References/PyTorch/nlp/pretraining/deepspeed-bert/scripts# ./run_bert_large.sh
[2022-08-03 06:37:21,466] [INFO] [multinode_runner.py:65:get_cmd] Running on the following workers: 172.31.81.82,172.31.94.102
[2022-08-03 06:37:21,467] [INFO] [runner.py:466:main] cmd = pdsh -f 1024 -w 172.31.81.82,172.31.94.102 export PYTHONPATH=/Model-References/PyTorch/nlp/pretraining/deepspeed-bert/scripts:/root:/usr/lib/habanalabs/:/Model-References; export HCCL_OVER_TCP=0; export HCCL_OVER_OFI=1; export HCCL_SOCKET_IFNAME=eth0; export LD_LIBRARY_PATH=/root/hccl_ofi_wrapper:/opt/amazon/openmpi/lib:/opt/amazon/efa/lib; cd /Model-References/PyTorch/nlp/pretraining/deepspeed-bert/scripts; /usr/bin/python3 -u -m deepspeed.launcher.launch --world_info=eyIxNzIuMzEuODEuODIiOiBbMCwgMSwgMiwgMywgNCwgNSwgNiwgN10sICIxNzIuMzEuOTQuMTAyIjogWzAsIDEsIDIsIDMsIDQsIDUsIDYsIDddfQ== --node_rank=%n --master_addr=172.31.81.82 --master_port=29500 --no_python --no_local_rank /usr/bin/bash -c 'source /activate ; cd /Model-References/PyTorch/nlp/pretraining/deepspeed-bert/scripts && python -u ../run_pretraining.py --use_hpu --warmup_proportion=0.2843 --resume_from_checkpoint --do_train --bert_model=bert-base-uncased --config_file=./bert_large_config.json --json-summary=../results/bert_large/dllogger.json --output_dir=../results/bert_large/checkpoints --seed=12439 --optimizer=nvlamb --use_lr_scheduler --input_dir=/mnt/efs/hdf5_dataset/hdf5_lower_case_1_seq_len_128_max_pred_20_masked_lm_prob_0.15_random_seed_12345_dupe_factor_5/wikicorpus_en --max_seq_length 128 --max_predictions_per_seq=20 --max_steps=7038 --num_steps_per_checkpoint=200 --learning_rate=0.006 --deepspeed --deepspeed_config=./deepspeed_config_bert_large.json'
172.31.81.82: Warning: Permanently added '[172.31.81.82]:2022' (RSA) to the list of known hosts.
172.31.94.102: Warning: Permanently added '[172.31.94.102]:2022' (RSA) to the list of known hosts.
172.31.81.82: [2022-08-03 06:37:22,500] [INFO] [launch.py:104:main] WORLD INFO DICT: {'172.31.81.82': [0, 1, 2, 3, 4, 5, 6, 7], '172.31.94.102': [0, 1, 2, 3, 4, 5, 6, 7]}
172.31.81.82: [2022-08-03 06:37:22,500] [INFO] [launch.py:110:main] nnodes=2, num_local_procs=8, node_rank=0
172.31.81.82: [2022-08-03 06:37:22,500] [INFO] [launch.py:123:main] global_rank_mapping=defaultdict(<class 'list'>, {'172.31.81.82': [0, 1, 2, 3, 4, 5, 6, 7], '172.31.94.102': [8, 9, 10, 11, 12, 13, 14, 15]})
172.31.81.82: [2022-08-03 06:37:22,500] [INFO] [launch.py:124:main] dist_world_size=16
172.31.94.102: [2022-08-03 06:37:22,528] [INFO] [launch.py:104:main] WORLD INFO DICT: {'172.31.81.82': [0, 1, 2, 3, 4, 5, 6, 7], '172.31.94.102': [0, 1, 2, 3, 4, 5, 6, 7]}
172.31.94.102: [2022-08-03 06:37:22,528] [INFO] [launch.py:110:main] nnodes=2, num_local_procs=8, node_rank=1
172.31.94.102: [2022-08-03 06:37:22,528] [INFO] [launch.py:123:main] global_rank_mapping=defaultdict(<class 'list'>, {'172.31.81.82': [0, 1, 2, 3, 4, 5, 6, 7], '172.31.94.102': [8, 9, 10, 11, 12, 13, 14, 15]})
172.31.94.102: [2022-08-03 06:37:22,528] [INFO] [launch.py:124:main] dist_world_size=16
172.31.81.82: Distributed training with backend=hccl, device=hpu, local_rank=1
172.31.81.82: Distributed training with backend=hccl, device=hpu, local_rank=0
172.31.81.82: Distributed training with backend=hccl, device=hpu, local_rank=3
172.31.81.82: [2022-08-03 06:37:23,169] [INFO] [distributed.py:46:init_distributed] Initializing torch distributed with backend: hccl
172.31.81.82: Distributed training with backend=hccl, device=hpu, local_rank=5
172.31.81.82: Distributed training with backend=hccl, device=hpu, local_rank=4
172.31.81.82: Distributed training with backend=hccl, device=hpu, local_rank=2Distributed training with backend=hccl, device=hpu, local_rank=6
172.31.81.82:
172.31.81.82: Distributed training with backend=hccl, device=hpu, local_rank=7
172.31.94.102: Distributed training with backend=hccl, device=hpu, local_rank=7
172.31.94.102: Distributed training with backend=hccl, device=hpu, local_rank=3Distributed training with backend=hccl, device=hpu, local_rank=0Distributed training with backend=hccl, device=hpu, local_rank=6
172.31.94.102:
172.31.94.102:
172.31.94.102: Distributed training with backend=hccl, device=hpu, local_rank=2
172.31.94.102: Distributed training with backend=hccl, device=hpu, local_rank=4
172.31.94.102: Distributed training with backend=hccl, device=hpu, local_rank=5
172.31.94.102: Distributed training with backend=hccl, device=hpu, local_rank=1
172.31.81.82: DLL 2022-08-03 06:37:24.177836 - PARAMETER Config : ["Namespace(bert_model='bert-base-uncased', config_file='./bert_large_config.json', constant_proportion=0.0, deepscale=False, deepscale_config=None, deepspeed=True, deepspeed_config='./deepspeed_config_bert_large.json', deepspeed_mpi=False, disable_progress_bar=False, do_train=True, init_loss_scale=1048576, input_dir='/mnt/efs/hdf5_dataset/hdf5_lower_case_1_seq_len_128_max_pred_20_masked_lm_prob_0.15_random_seed_12345_dupe_factor_5/wikitext-2', json_summary='../results/bert_large/dllogger.json', learning_rate=0.006, local_rank=0, log_bwd_grads=False, log_freq=1.0, log_fwd_activations=False, log_model_inputs=False, loss_scale=0.0, max_predictions_per_seq=20, max_seq_length=128, max_steps=7038.0, no_cuda=False, num_steps_per_checkpoint=200, num_train_epochs=3.0, optimizer='nvlamb', output_dir='../results/bert_large/checkpoints', phase1_end_step=7038, phase2=False, rank=0, resume_from_checkpoint=True, resume_step=-1, scheduler_degree=1.0, seed=12439, skip_checkpoint=False, steps_this_run=7038.0, tensor_logger_max_iterations=0, tensor_logger_path=None, use_env=False, use_hpu=True, use_lazy_mode=True, use_lr_scheduler=True, warmup_proportion=0.2843, world_size=16, zero_optimization=True)"]
172.31.94.102: Using NVLamb
172.31.94.102: Using PolyWarmUpScheduler with args={'warmup': 0.2843, 'total_steps': 7038.0, 'degree': 1.0, 'constant': 0.0}
172.31.94.102: Using NVLamb
172.31.94.102: Using PolyWarmUpScheduler with args={'warmup': 0.2843, 'total_steps': 7038.0, 'degree': 1.0, 'constant': 0.0}
172.31.81.82: Using NVLamb
172.31.81.82: Using PolyWarmUpScheduler with args={'warmup': 0.2843, 'total_steps': 7038.0, 'degree': 1.0, 'constant': 0.0}
172.31.81.82: Using NVLamb
172.31.81.82: Using PolyWarmUpScheduler with args={'warmup': 0.2843, 'total_steps': 7038.0, 'degree': 1.0, 'constant': 0.0}
172.31.81.82: [2022-08-03 06:37:31,125] [INFO] [logging.py:69:log_dist] [Rank 0] DeepSpeed info: version=0.6.1+0f2b744, git-hash=0f2b744, git-branch=v1.5.0
172.31.94.102: Using NVLamb
172.31.94.102: Using PolyWarmUpScheduler with args={'warmup': 0.2843, 'total_steps': 7038.0, 'degree': 1.0, 'constant': 0.0}
172.31.94.102: Using NVLamb
172.31.94.102: Using PolyWarmUpScheduler with args={'warmup': 0.2843, 'total_steps': 7038.0, 'degree': 1.0, 'constant': 0.0}
172.31.94.102: Using NVLamb
172.31.94.102: Using PolyWarmUpScheduler with args={'warmup': 0.2843, 'total_steps': 7038.0, 'degree': 1.0, 'constant': 0.0}
172.31.94.102: Using NVLamb
172.31.94.102: Using PolyWarmUpScheduler with args={'warmup': 0.2843, 'total_steps': 7038.0, 'degree': 1.0, 'constant': 0.0}
172.31.81.82: Using NVLamb
172.31.81.82: Using PolyWarmUpScheduler with args={'warmup': 0.2843, 'total_steps': 7038.0, 'degree': 1.0, 'constant': 0.0}
172.31.94.102: Using NVLamb
172.31.94.102: Using PolyWarmUpScheduler with args={'warmup': 0.2843, 'total_steps': 7038.0, 'degree': 1.0, 'constant': 0.0}
172.31.81.82: Using NVLamb
172.31.81.82: Using NVLamb
172.31.81.82: Using PolyWarmUpScheduler with args={'warmup': 0.2843, 'total_steps': 7038.0, 'degree': 1.0, 'constant': 0.0}
172.31.81.82: Using PolyWarmUpScheduler with args={'warmup': 0.2843, 'total_steps': 7038.0, 'degree': 1.0, 'constant': 0.0}
172.31.81.82: Using NVLamb
172.31.81.82: Using PolyWarmUpScheduler with args={'warmup': 0.2843, 'total_steps': 7038.0, 'degree': 1.0, 'constant': 0.0}
172.31.81.82: Using NVLamb
172.31.81.82: Using PolyWarmUpScheduler with args={'warmup': 0.2843, 'total_steps': 7038.0, 'degree': 1.0, 'constant': 0.0}
172.31.81.82: Using NVLamb
172.31.81.82: Using PolyWarmUpScheduler with args={'warmup': 0.2843, 'total_steps': 7038.0, 'degree': 1.0, 'constant': 0.0}
172.31.94.102: Using NVLamb
172.31.94.102: Using PolyWarmUpScheduler with args={'warmup': 0.2843, 'total_steps': 7038.0, 'degree': 1.0, 'constant': 0.0}
172.31.81.82: [2022-08-03 06:37:34,795] [INFO] [engine.py:310:__init__] DeepSpeed Flops Profiler Enabled: False
172.31.81.82: Having --resume_from_checkpoint, but no valid checkpoint found. Starting from scratch.
...
...
172.31.81.82: [2022-08-03 06:38:44,157] [INFO] [timer.py:191:stop] 0/10, SamplesPerSec=4365.047034883292, MemAllocated=10.8GB, MaxMemAllocated=10.8GB
172.31.81.82: [2022-08-03 06:38:45,386] [INFO] [timer.py:191:stop] 0/20, SamplesPerSec=4375.950582343779, MemAllocated=11.83GB, MaxMemAllocated=11.83GB
172.31.81.82: [2022-08-03 06:38:46,624] [INFO] [timer.py:191:stop] 0/30, SamplesPerSec=4364.670776539131, MemAllocated=12.87GB, MaxMemAllocated=12.87GB
172.31.81.82: [2022-08-03 06:38:47,869] [INFO] [timer.py:191:stop] 0/40, SamplesPerSec=4353.364008178977, MemAllocated=13.93GB, MaxMemAllocated=13.93GB
172.31.81.82: [2022-08-03 06:38:49,167] [INFO] [timer.py:191:stop] 0/50, SamplesPerSec=4304.457369031983, MemAllocated=14.73GB, MaxMemAllocated=14.99GB
172.31.81.82: [2022-08-03 06:38:50,379] [INFO] [timer.py:191:stop] 0/60, SamplesPerSec=4326.7731067092745, MemAllocated=15.8GB, MaxMemAllocated=15.8GB
172.31.81.82: [2022-08-03 06:38:51,639] [INFO] [timer.py:191:stop] 0/70, SamplesPerSec=4317.929920318314, MemAllocated=16.87GB, MaxMemAllocated=16.87GB
172.31.81.82: [2022-08-03 06:38:52,920] [INFO] [timer.py:191:stop] 0/80, SamplesPerSec=4300.453792895367, MemAllocated=17.92GB, MaxMemAllocated=17.92GB
172.31.81.82: [2022-08-03 06:38:54,376] [INFO] [timer.py:191:stop] 0/90, SamplesPerSec=4217.847501265665, MemAllocated=18.47GB, MaxMemAllocated=18.74GB
172.31.81.82: [2022-08-03 06:38:56,391] [INFO] [timer.py:191:stop] 0/100, SamplesPerSec=3970.71850399855, MemAllocated=18.55GB, MaxMemAllocated=18.81GB
172.31.81.82: [2022-08-03 06:38:58,407] [INFO] [timer.py:191:stop] 0/110, SamplesPerSec=3789.5025973069182, MemAllocated=18.61GB, MaxMemAllocated=18.86GB
General observations
With this approach the team has been able to scale the training with as much as 32 nodes (32 * 8 = 256 Gaudis).