h. Submit MNP Job via Console
In this section
- Submit a MNP job (2 nodes) through the AWS Batch console
- SSH into the master container and verify the communication in the cluster
- Validate the NCCL communication between the containers
- Deepspeed training on a single node
- Launch Multi Node Deep Speed training with Mistral
High Level MNP Job Setup
In a production environment, it’s important to efficiently execute the compute workload with multi-node parallel jobs. Most of the optimization is on the application layer and how efficiently the Message Passing Interface (MPI) ranks (MPI and OpenMP threads) are distributed across nodes.
The key requirements for running a MNP job on AWS Batch is a
- Dockerized image with
- application libraries, scripts, and code
- MPI stack for the tightly coupled communication layer
- Docker to Docker Communication
- Passwordless ssh ability from one node to another
- Running child Docker containers need to pass container IP address information to the master node to fill out the MPI host file
- Wrapper script for the MPI orchestration (Packaged into the container)
The undifferentiated heavy lifting that AWS Batch provides is the Docker-to-Docker communication across nodes using Amazon ECS task networking. With multi-node parallel jobs, the ECS container receives environmental variables from the backend, which can be used to establish which running container is the master and which is the child.
| ENV Variable | Description |
|---|---|
| AWS_BATCH_JOB_MAIN_NODE_INDEX | The designation of the master node in a multi-node parallel job. This is the main node in which the MPI job is launched. |
| AWS_BATCH_JOB_MAIN_NODE_PRIVATE_IPV4_ADDRESS | The IPv4 address of the main node. This is presented in the environment for all children nodes. |
| AWS_BATCH_JOB_NUM_NODES | The number of nodes launched as part of the node group for your multi-node parallel job. |
When the docker container starts up, a supervisor script executes the commands in order
- SSHD Setup
- Triggers the ssh-daemon to start in Port 2022
- Point the id_rsa to the “same” key that is present in all the containers as a part of the build process
- This is fundamental to enable passwordless ssh across different containers
- Discovery of Child & Master workers
- Environment variables are used to determine if the container instance is a Child or a Master. For example, If AWS_BATCH_JOB_MAIN_NODE_INDEX = AWS_BATCH_JOB_NODE_INDEX, then this is the main node.
- MNP automatically assigns each Container with an IP Address that is needed for container task networking
- The code in prep_mpi_run.sh provides the MPI synchronization
- Incorporate simple health checks on the instance being launched into the pool. Any bad instances can be tagged and removed off the pool so that it does not result in a failed overall run.
- Broadly, there are two different types of action
- Master Node: Will wait for all the child nodes to report their IP
- Child Node: Will report their Container IP address obtained via (hostname -i)
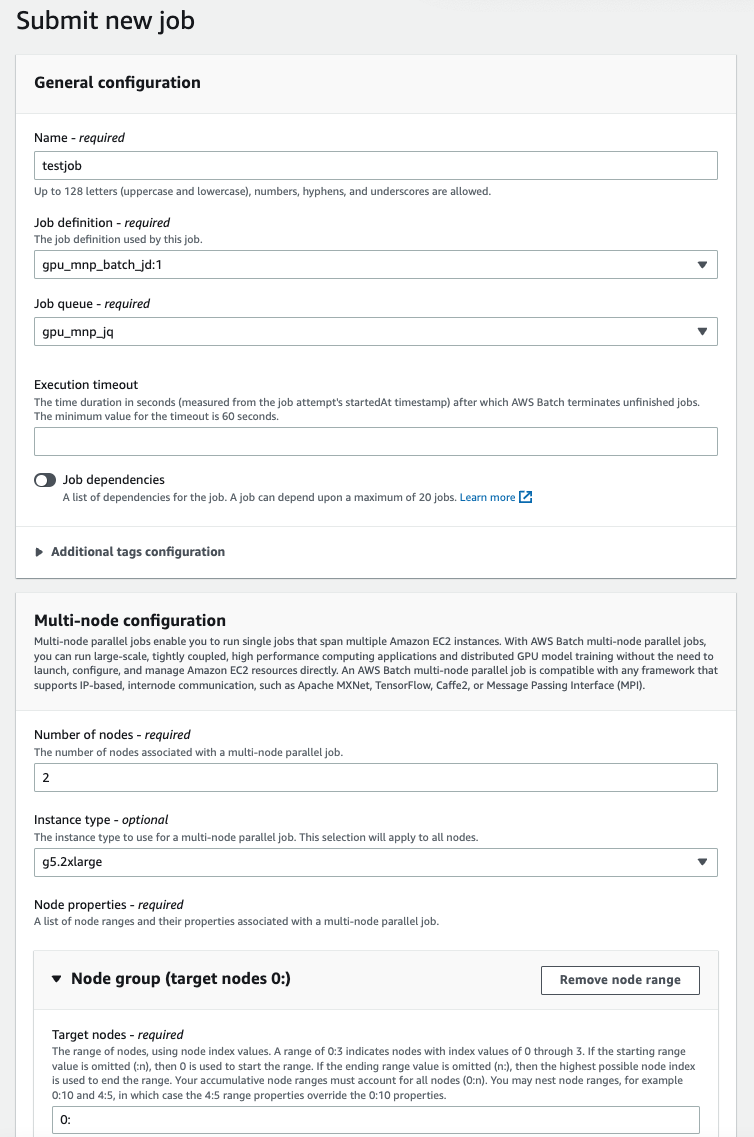
Submit a new Job
From the AWS Batch Console, click on Job Definition and then the MNP job definition which was just created.
- Click on new submit a new job
- Set the Name as testjob
- Set the JobQueue as gpu_mnp_jq (from the downselect)
- Multi Node Configuration
- Number of Nodes (Can be modified to the total number of nodes we want in our training)
- Leave the others at default (since they are automatically picked up from the job definition)
Screenshot of the Job submission dialog is shown below
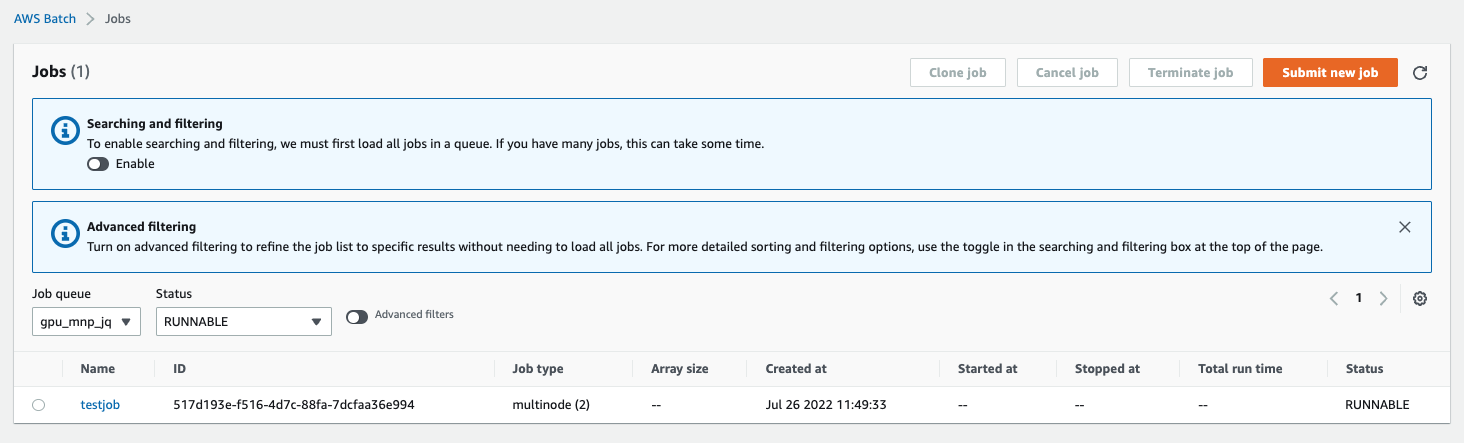
After the job submit, the job will go to a Runnable State
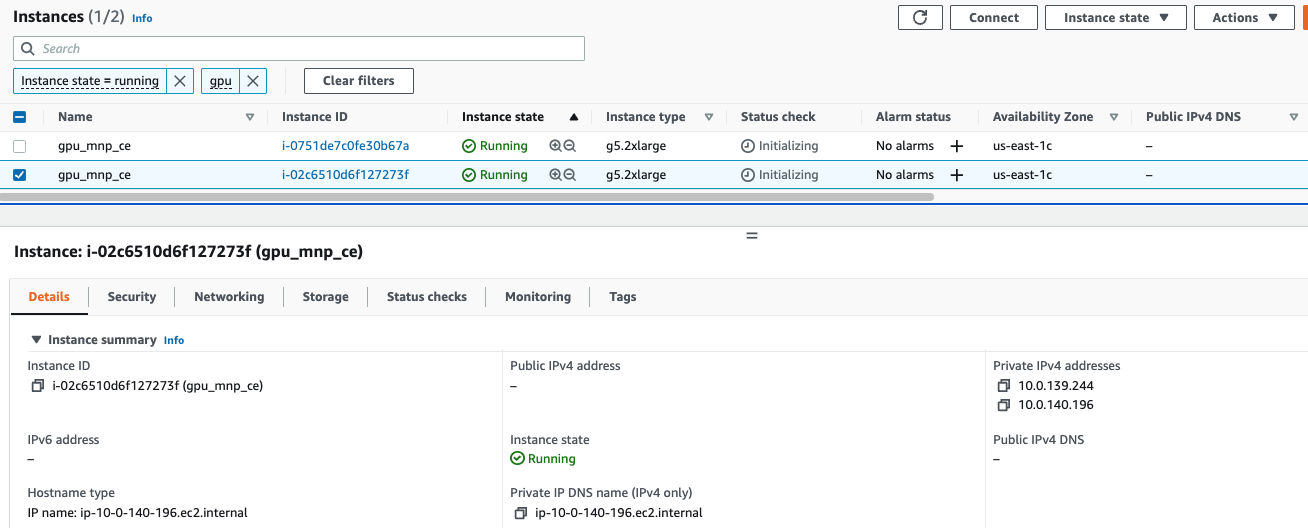
Sequence of Instance Launch and IP assignment
Even though both the instances startup, the master node will be the first to pull the container. This is clearly seen by the 2 private ip’s that get assigned to the master node (1 for the instance and 1 for the container). At the same time, the child node has only the instance ip
Master Node having 2 ip’s
At the same time the Child Node has only 1 ip
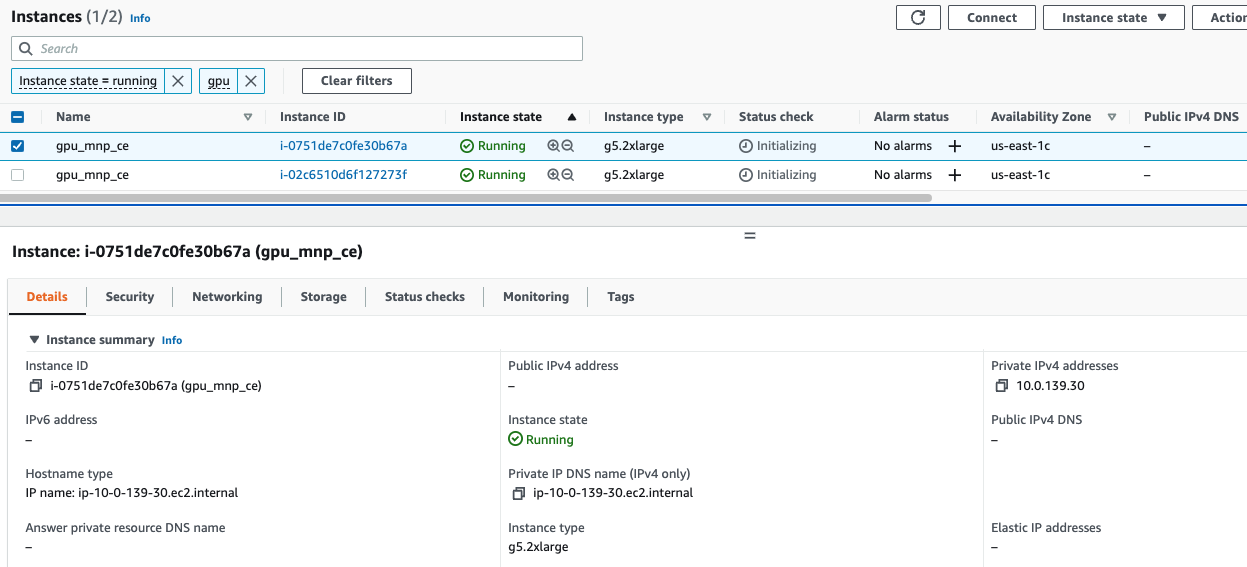
After the Master has started up, the containers will be downloaded onto the child nodes and it will also get 2 IP’s
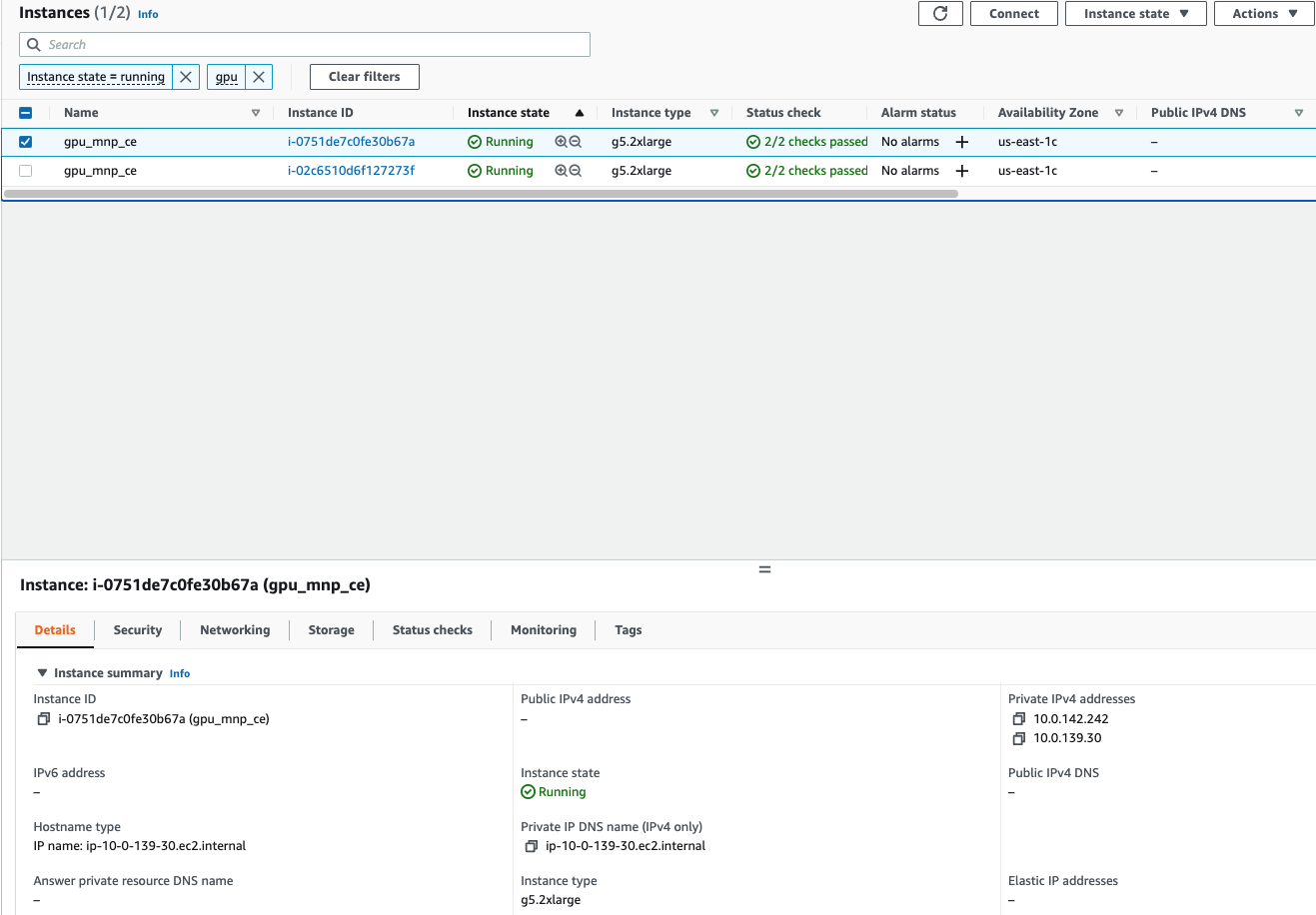
Logging into the Master Node
-
Determine the ssh connect information from the instance by right clicking on the instance in the EC2 console
-
Use the Cloud9 to connect to your Master Node. The Cloud9 instance is in your public subnet and can be used to connect to your instances in the private subnet. You have to copy your *.pem file to your Cloud9 instance to use it as credentials for the ssh
ssh -i "xxxxxxx.pem" ec2-user@10.0.140.196
__| __| __|
_| ( \__ \ Amazon Linux 2 (ECS Optimized)
____|\___|____/
For documentation, visit http://aws.amazon.com/documentation/ecs
17 package(s) needed for security, out of 47 available
Run "sudo yum update" to apply all updates.
- Verify the Containers running on the master node
[ec2-user@ip-10-0-140-196 ~]$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
aac8885ecdd8 01234567890.dkr.ecr.us-east-1.amazonaws.com/g5_train:v1 "/bin/sh -c /entry-p…" 3 minutes ago Up 3 minutes ecs-gpu_mnp_batch_jd_0-1-2-default-d4e9b3dfc6f0d3f33c00
b4a59eea4287 amazon/amazon-ecs-pause:0.1.0 "/pause" 8 minutes ago Up 8 minutes ecs-gpu_mnp_batch_jd_0-1-2-internalecspause-a2b0959aeec980946400
875b9d23d94d amazon/amazon-ecs-agent:latest "/agent" 8 minutes ago Up 8 minutes (healthy) ecs-agent
- Check the logs of the container. Initially the master node is only part of the pool and it waits until all the child nodes join the pool
[ec2-user@ip-10-0-140-196 ~]$ docker logs aac
2022-07-26 18:55:34,459 CRIT Supervisor is running as root. Privileges were not dropped because no user is specified in the config file. If you intend to run as root, you can set user=root in the config file to avoid this message.
2022-07-26 18:55:34,460 INFO supervisord started with pid 8
2022-07-26 18:55:35,462 INFO spawned: 'sshd' with pid 10
2022-07-26 18:55:35,463 INFO spawned: 'synchronize' with pid 11
prep_mpi_run.sh - Running synchronize as the main node
2022-07-26 18:55:35,466 INFO success: synchronize entered RUNNING state, process has stayed up for > than 0 seconds (startsecs)
prep_mpi_run.sh - main
prep_mpi_run.sh - Running as master node
prep_mpi_run.sh - master details -> 10.0.139.244:1
prep_mpi_run.sh - 1 out of 2 nodes joined, check again in 1 second
2022-07-26 18:55:36,473 INFO success: sshd entered RUNNING state, process has stayed up for > than 1 seconds (startsecs)
prep_mpi_run.sh - 1 out of 2 nodes joined, check again in 1 second
.....
prep_mpi_run.sh - 1 out of 2 nodes joined, check again in 1 second
- After the Child node starts up and the container is up and running, it will report its IP to the master. At this point the log file in the master would confirm “successful” join by all the child nodes and the hostfile would be created in /tmp/hostfile
prep_mpi_run.sh - 1 out of 2 nodes joined, check again in 1 second
prep_mpi_run.sh - All nodes successfully joined
10.0.139.244 slots=1
10.0.142.242 slots=1
prep_mpi_run.sh - executing main MPIRUN workflow
Tue Jul 26 19:00:07 UTC 2022
Tue Jul 26 19:01:07 UTC 2022
In this case,
- The first IP is for the container on the master node
- The second IP is the container on the child node
- If you have more than 2 nodes, the IP’s will be captured in the hostfile
Check the NCCL runs on Single Node and Multiple Nodes
- Exec into the Master Node using docker exec. The /workspace folder has all the scripts installed during the container build process
[ec2-user@ip-10-0-140-196 ~]$ docker exec -it aac /bin/bash
root@ip-10-0-139-244:/workspace# ls -lrt
total 45980
drwxr-xr-x 3 root root 78 Jul 22 18:20 aws
-rw-r--r-- 1 root root 126 Jul 25 00:07 requirements.txt
-rw-r--r-- 1 root root 47059501 Jul 26 03:02 awscliv2.zip
drwxr-xr-x 7 root root 4096 Jul 26 03:02 mpitutorial
drwxr-xr-x 6 root root 123 Jul 26 03:02 nccl-tests
drwxr-xr-x 27 root root 4096 Jul 26 03:03 pytorch
drwxr-xr-x 15 root root 4096 Jul 26 03:05 transformers
drwxr-xr-x 12 root root 4096 Jul 26 03:05 mistral
- NCCL tests are present in the nccl-tests folder in the container. First we will trigger the mpirun on the container in the master node
root@ip-10-0-139-244:/workspace# cd nccl-tests/
root@ip-10-0-139-244:/workspace/nccl-tests/build# pwd
/workspace/nccl-tests/build
root@ip-10-0-139-244:/workspace/nccl-tests/build# cat /tmp/hostfile
10.0.139.244 slots=1
10.0.142.242 slots=1
root@ip-10-0-139-244:/workspace/nccl-tests/build# mpirun -host 10.0.139.244 -np 1 all_reduce_perf -b 8 -e 128M -f 2 -g 1
# nThread 1 nGpus 1 minBytes 8 maxBytes 134217728 step: 2(factor) warmup iters: 5 iters: 20 validation: 1
#
# Using devices
# Rank 0 Pid 1428 on ip-10-0-139-244 device 0 [0x00] NVIDIA A10G
#
# out-of-place in-place
# size count type redop time algbw busbw error time algbw busbw error
# (B) (elements) (us) (GB/s) (GB/s) (us) (GB/s) (GB/s)
8 2 float sum 4.17 0.00 0.00 0e+00 0.58 0.01 0.00 0e+00
16 4 float sum 4.28 0.00 0.00 0e+00 0.58 0.03 0.00 0e+00
32 8 float sum 4.28 0.01 0.00 0e+00 0.67 0.05 0.00 0e+00
64 16 float sum 5.92 0.01 0.00 0e+00 0.57 0.11 0.00 0e+00
128 32 float sum 4.90 0.03 0.00 0e+00 0.58 0.22 0.00 0e+00
256 64 float sum 5.82 0.04 0.00 0e+00 0.64 0.40 0.00 0e+00
512 128 float sum 4.95 0.10 0.00 0e+00 0.59 0.87 0.00 0e+00
1024 256 float sum 4.49 0.23 0.00 0e+00 0.80 1.29 0.00 0e+00
2048 512 float sum 4.85 0.42 0.00 0e+00 0.57 3.57 0.00 0e+00
4096 1024 float sum 4.78 0.86 0.00 0e+00 0.57 7.18 0.00 0e+00
8192 2048 float sum 4.73 1.73 0.00 0e+00 0.58 14.14 0.00 0e+00
16384 4096 float sum 5.02 3.27 0.00 0e+00 0.57 28.57 0.00 0e+00
32768 8192 float sum 4.79 6.85 0.00 0e+00 0.58 56.01 0.00 0e+00
65536 16384 float sum 4.82 13.58 0.00 0e+00 0.57 115.89 0.00 0e+00
131072 32768 float sum 4.87 26.94 0.00 0e+00 0.58 224.82 0.00 0e+00
262144 65536 float sum 4.80 54.65 0.00 0e+00 0.58 455.51 0.00 0e+00
524288 131072 float sum 4.94 106.20 0.00 0e+00 0.73 717.22 0.00 0e+00
1048576 262144 float sum 6.69 156.78 0.00 0e+00 0.58 1797.05 0.00 0e+00
2097152 524288 float sum 11.45 183.08 0.00 0e+00 0.58 3606.45 0.00 0e+00
4194304 1048576 float sum 20.58 203.80 0.00 0e+00 0.58 7237.80 0.00 0e+00
8388608 2097152 float sum 38.71 216.70 0.00 0e+00 0.58 14586.35 0.00 0e+00
16777216 4194304 float sum 73.17 229.29 0.00 0e+00 0.58 28728.11 0.00 0e+00
33554432 8388608 float sum 141.6 236.96 0.00 0e+00 0.59 57109.07 0.00 0e+00
67108864 16777216 float sum 278.4 241.06 0.00 0e+00 0.59 113637.90 0.00 0e+00
134217728 33554432 float sum 552.1 243.09 0.00 0e+00 0.58 232613.05 0.00 0e+00
# Out of bounds values : 0 OK
# Avg bus bandwidth : 0
#
- Trigger the nccl-test on the child node from the master node by specifying the child IP in the mpirun for the host
root@ip-10-0-139-244:/workspace/nccl-tests/build# mpirun -host 10.0.142.242 -np 1 all_reduce_perf -b 8 -e 128M -f 2 -g 1
Warning: Permanently added '[10.0.142.242]:2022' (RSA) to the list of known hosts.
# nThread 1 nGpus 1 minBytes 8 maxBytes 134217728 step: 2(factor) warmup iters: 5 iters: 20 validation: 1
#
# Using devices
# Rank 0 Pid 29 on ip-10-0-142-242 device 0 [0x00] NVIDIA A10G
#
# out-of-place in-place
# size count type redop time algbw busbw error time algbw busbw error
# (B) (elements) (us) (GB/s) (GB/s) (us) (GB/s) (GB/s)
8 2 float sum 4.41 0.00 0.00 0e+00 0.56 0.01 0.00 0e+00
16 4 float sum 4.24 0.00 0.00 0e+00 0.57 0.03 0.00 0e+00
32 8 float sum 4.24 0.01 0.00 0e+00 0.57 0.06 0.00 0e+00
64 16 float sum 4.30 0.01 0.00 0e+00 0.57 0.11 0.00 0e+00
128 32 float sum 4.31 0.03 0.00 0e+00 0.57 0.23 0.00 0e+00
256 64 float sum 4.28 0.06 0.00 0e+00 0.57 0.45 0.00 0e+00
512 128 float sum 4.26 0.12 0.00 0e+00 0.56 0.92 0.00 0e+00
1024 256 float sum 4.28 0.24 0.00 0e+00 0.56 1.82 0.00 0e+00
2048 512 float sum 4.26 0.48 0.00 0e+00 0.57 3.59 0.00 0e+00
4096 1024 float sum 4.27 0.96 0.00 0e+00 0.58 7.01 0.00 0e+00
8192 2048 float sum 4.25 1.93 0.00 0e+00 0.57 14.31 0.00 0e+00
16384 4096 float sum 4.24 3.86 0.00 0e+00 0.57 28.69 0.00 0e+00
32768 8192 float sum 4.32 7.59 0.00 0e+00 0.57 57.95 0.00 0e+00
65536 16384 float sum 4.32 15.17 0.00 0e+00 0.56 116.20 0.00 0e+00
131072 32768 float sum 4.31 30.44 0.00 0e+00 0.57 229.55 0.00 0e+00
262144 65536 float sum 4.34 60.39 0.00 0e+00 0.57 459.90 0.00 0e+00
524288 131072 float sum 4.39 119.32 0.00 0e+00 0.57 924.59 0.00 0e+00
1048576 262144 float sum 6.64 157.93 0.00 0e+00 0.66 1591.16 0.00 0e+00
2097152 524288 float sum 11.23 186.73 0.00 0e+00 0.56 3731.59 0.00 0e+00
4194304 1048576 float sum 20.80 201.68 0.00 0e+00 0.57 7409.78 0.00 0e+00
8388608 2097152 float sum 38.78 216.33 0.00 0e+00 0.56 14847.09 0.00 0e+00
16777216 4194304 float sum 73.05 229.67 0.00 0e+00 0.57 29670.56 0.00 0e+00
33554432 8388608 float sum 141.4 237.22 0.00 0e+00 0.56 59599.35 0.00 0e+00
67108864 16777216 float sum 278.3 241.18 0.00 0e+00 0.57 117631.66 0.00 0e+00
134217728 33554432 float sum 552.3 243.04 0.00 0e+00 0.58 233219.34 0.00 0e+00
# Out of bounds values : 0 OK
# Avg bus bandwidth : 0
#
- Trigger the nccl-test with two nodes and two processes. Very important to set the NCCL_SOCKET_IFNAME to be eth0 and NCCL_DEBUG=INFO to get detailed message during the test
root@ip-10-0-139-244:/workspace/nccl-tests/build# mpirun -x NCCL_DEBUG=INFO -x NCCL_SOCKET_IFNAME=eth0 -host 10.0.139.244,10.0.142.242 -np 2 all_reduce_perf -b 8 -e 128M -f 2 -g 1
Warning: Permanently added '[10.0.142.242]:2022' (RSA) to the list of known hosts.
# nThread 1 nGpus 1 minBytes 8 maxBytes 134217728 step: 2(factor) warmup iters: 5 iters: 20 validation: 1
#
# Using devices
# Rank 0 Pid 1465 on ip-10-0-139-244 device 0 [0x00] NVIDIA A10G
# Rank 1 Pid 46 on ip-10-0-142-242 device 0 [0x00] NVIDIA A10G
ip-10-0-139-244:1465:1465 [0] NCCL INFO Bootstrap : Using eth0:10.0.139.244<0>
ip-10-0-139-244:1465:1465 [0] NCCL INFO NET/Plugin : Plugin load returned 17 : libnccl-net.so: cannot open shared object file: No such file or directory.
ip-10-0-139-244:1465:1465 [0] NCCL INFO Failed to open libibverbs.so[.1]
ip-10-0-139-244:1465:1465 [0] NCCL INFO NET/Socket : Using [0]eth0:10.0.139.244<0>
ip-10-0-139-244:1465:1465 [0] NCCL INFO Using network Socket
NCCL version 2.11.4+cuda11.4
ip-10-0-142-242:46:46 [0] NCCL INFO Bootstrap : Using eth0:10.0.142.242<0>
ip-10-0-142-242:46:46 [0] NCCL INFO NET/Plugin : No plugin found (libnccl-net.so), using internal implementation
ip-10-0-142-242:46:46 [0] NCCL INFO Failed to open libibverbs.so[.1]
ip-10-0-142-242:46:46 [0] NCCL INFO NET/Socket : Using [0]eth0:10.0.142.242<0>
ip-10-0-142-242:46:46 [0] NCCL INFO Using network Socket
ip-10-0-139-244:1465:1471 [0] NCCL INFO Channel 00/02 : 0 1
ip-10-0-139-244:1465:1471 [0] NCCL INFO Channel 01/02 : 0 1
ip-10-0-139-244:1465:1471 [0] NCCL INFO Trees [0] 1/-1/-1->0->-1 [1] -1/-1/-1->0->1
ip-10-0-142-242:46:51 [0] NCCL INFO Trees [0] -1/-1/-1->1->0 [1] 0/-1/-1->1->-1
ip-10-0-142-242:46:51 [0] NCCL INFO Channel 00 : 0[1e0] -> 1[1e0] [receive] via NET/Socket/0
ip-10-0-142-242:46:51 [0] NCCL INFO NET/Socket: Using 2 threads and 8 sockets per thread
ip-10-0-139-244:1465:1471 [0] NCCL INFO Channel 00 : 1[1e0] -> 0[1e0] [receive] via NET/Socket/0
ip-10-0-139-244:1465:1471 [0] NCCL INFO NET/Socket: Using 2 threads and 8 sockets per thread
ip-10-0-142-242:46:51 [0] NCCL INFO Channel 01 : 0[1e0] -> 1[1e0] [receive] via NET/Socket/0
ip-10-0-142-242:46:51 [0] NCCL INFO NET/Socket: Using 2 threads and 8 sockets per thread
ip-10-0-139-244:1465:1471 [0] NCCL INFO Channel 01 : 1[1e0] -> 0[1e0] [receive] via NET/Socket/0
ip-10-0-139-244:1465:1471 [0] NCCL INFO NET/Socket: Using 2 threads and 8 sockets per thread
ip-10-0-142-242:46:51 [0] NCCL INFO Channel 00 : 1[1e0] -> 0[1e0] [send] via NET/Socket/0
ip-10-0-139-244:1465:1471 [0] NCCL INFO Channel 00 : 0[1e0] -> 1[1e0] [send] via NET/Socket/0
ip-10-0-142-242:46:51 [0] NCCL INFO Channel 01 : 1[1e0] -> 0[1e0] [send] via NET/Socket/0
ip-10-0-139-244:1465:1471 [0] NCCL INFO Channel 01 : 0[1e0] -> 1[1e0] [send] via NET/Socket/0
ip-10-0-139-244:1465:1471 [0] NCCL INFO Connected all rings
ip-10-0-139-244:1465:1471 [0] NCCL INFO Connected all trees
ip-10-0-139-244:1465:1471 [0] NCCL INFO threadThresholds 8/8/64 | 16/8/64 | 8/8/512
ip-10-0-139-244:1465:1471 [0] NCCL INFO 2 coll channels, 2 p2p channels, 1 p2p channels per peer
ip-10-0-139-244:1465:1471 [0] NCCL INFO comm 0x7f85a4000fa0 rank 0 nranks 2 cudaDev 0 busId 1e0 - Init COMPLETE
ip-10-0-142-242:46:51 [0] NCCL INFO Connected all rings
ip-10-0-142-242:46:51 [0] NCCL INFO Connected all trees
ip-10-0-142-242:46:51 [0] NCCL INFO threadThresholds 8/8/64 | 16/8/64 | 8/8/512
ip-10-0-142-242:46:51 [0] NCCL INFO 2 coll channels, 2 p2p channels, 1 p2p channels per peer
#
# out-of-place in-place
# size count type redop time algbw busbw error time algbw busbw error
# (B) (elements) (us) (GB/s) (GB/s) (us) (GB/s) (GB/s)
ip-10-0-139-244:1465:1465 [0] NCCL INFO Launch mode Parallel
ip-10-0-142-242:46:51 [0] NCCL INFO comm 0x7f7dec000fa0 rank 1 nranks 2 cudaDev 0 busId 1e0 - Init COMPLETE
8 2 float sum 172.7 0.00 0.00 0e+00 168.9 0.00 0.00 0e+00
16 4 float sum 181.0 0.00 0.00 0e+00 180.8 0.00 0.00 0e+00
32 8 float sum 181.3 0.00 0.00 0e+00 178.1 0.00 0.00 0e+00
64 16 float sum 176.5 0.00 0.00 0e+00 179.0 0.00 0.00 0e+00
128 32 float sum 176.0 0.00 0.00 0e+00 187.5 0.00 0.00 0e+00
256 64 float sum 177.5 0.00 0.00 0e+00 174.8 0.00 0.00 0e+00
512 128 float sum 177.6 0.00 0.00 0e+00 175.7 0.00 0.00 0e+00
1024 256 float sum 187.5 0.01 0.01 0e+00 182.0 0.01 0.01 0e+00
2048 512 float sum 196.4 0.01 0.01 0e+00 198.0 0.01 0.01 0e+00
4096 1024 float sum 203.6 0.02 0.02 0e+00 218.8 0.02 0.02 0e+00
8192 2048 float sum 233.0 0.04 0.04 0e+00 240.9 0.03 0.03 0e+00
16384 4096 float sum 300.1 0.05 0.05 0e+00 304.9 0.05 0.05 0e+00
32768 8192 float sum 346.6 0.09 0.09 0e+00 346.3 0.09 0.09 0e+00
65536 16384 float sum 420.4 0.16 0.16 0e+00 421.2 0.16 0.16 0e+00
131072 32768 float sum 521.4 0.25 0.25 0e+00 523.5 0.25 0.25 0e+00
262144 65536 float sum 736.7 0.36 0.36 0e+00 657.8 0.40 0.40 0e+00
524288 131072 float sum 991.4 0.53 0.53 0e+00 1050.1 0.50 0.50 0e+00
1048576 262144 float sum 1762.4 0.59 0.59 0e+00 1704.5 0.62 0.62 0e+00
2097152 524288 float sum 2918.4 0.72 0.72 0e+00 2790.1 0.75 0.75 0e+00
4194304 1048576 float sum 5208.9 0.81 0.81 0e+00 4886.9 0.86 0.86 0e+00
8388608 2097152 float sum 12668 0.66 0.66 0e+00 11719 0.72 0.72 0e+00
16777216 4194304 float sum 20366 0.82 0.82 0e+00 20672 0.81 0.81 0e+00
33554432 8388608 float sum 43233 0.78 0.78 0e+00 43279 0.78 0.78 0e+00
67108864 16777216 float sum 87624 0.77 0.77 0e+00 84776 0.79 0.79 0e+00
134217728 33554432 float sum 183560 0.73 0.73 0e+00 174589 0.77 0.77 0e+00
# Out of bounds values : 0 OK
# Avg bus bandwidth : 0.300212
root@ip-10-0-139-244:/workspace/nccl-tests/build#
Disable Weights And Bias (WANDB)
- Given that our training happens in a private subnet, we need to turn off the wandb so that we do not have issues related to ports accessing the outside world. Sometimes, it can ask for user input to confirm the option selection. Hence, we disable wandb
root@ip-10-0-143-177:/workspace/transformers# wandb off
wW&B offline, running your script from this directory will only write metadata locally.
root@ip-10-0-143-177:/workspace/transformers# wandb disabled
W&B disabled.
Deep Speed Example on a single node
- Enable the NCCL_DEBUG environment variable level to INFO to observe the messages
export NCCL_DEBUG=INFO
- Execute the deepspeed examples from the transformers library. Launch the single node run from the master where the NLP training (t5-small model - 60 million parameters) will be done with local resources. The output has been provided here for your reference.
root@ip-10-0-139-244:/workspace/transformers# deepspeed examples/pytorch/translation/run_translation.py --deepspeed tests/deepspeed/ds_config_zero3.json --model_name_or_path t5-small --per_device_train_batch_size 1 --output_dir output_dir --overwrite_output_dir --fp16 --do_train --max_train_samples 500 --num_train_epochs 1 --dataset_name wmt16 --dataset_config "ro-en" --source_lang en --target_lang ro
[2022-07-26 19:14:55,449] [WARNING] [runner.py:159:fetch_hostfile] Unable to find hostfile, will proceed with training with local resources only.
...
...
Loading extension module utils...
Time to load utils op: 0.0003139972686767578 seconds
[INFO|trainer.py:1605] 2022-07-26 19:15:43,851 >> ***** Running training *****
[INFO|trainer.py:1606] 2022-07-26 19:15:43,851 >> Num examples = 500
[INFO|trainer.py:1607] 2022-07-26 19:15:43,852 >> Num Epochs = 1
[INFO|trainer.py:1608] 2022-07-26 19:15:43,852 >> Instantaneous batch size per device = 1
[INFO|trainer.py:1609] 2022-07-26 19:15:43,852 >> Total train batch size (w. parallel, distributed & accumulation) = 1
[INFO|trainer.py:1610] 2022-07-26 19:15:43,852 >> Gradient Accumulation steps = 1
[INFO|trainer.py:1611] 2022-07-26 19:15:43,852 >> Total optimization steps = 500
0%| | 0/500 [00:00<?, ?it/s][2022-07-26 19:15:51,159] [INFO] [stage3.py:1834:_overflow_clean_up] [deepspeed] OVERFLOW! Rank 0 Skipping step. Attempted loss scale: 65536, reducing to 65536
0%|▍ | 1/500 [00:00<03:47, 2.19it/s][2022-07-26 19:15:52,710] [INFO] [stage3.py:1834:_overflow_clean_up] [deepspeed] OVERFLOW! Rank 0 Skipping step. Attempted loss scale: 65536, reducing to 32768.0
0%|▊ | 2/500 [00:02<09:07, 1.10s/it][2022-07-26 19:15:53,074] [INFO] [stage3.py:1834:_overflow_clean_up] [deepspeed] OVERFLOW! Rank 0 Skipping step. Attempted loss scale: 32768.0, reducing to 16384.0
1%|█▏ | 3/500 [00:02<06:19, 1.31it/s][2022-07-26 19:15:53,439] [INFO] [stage3.py:1834:_overflow_clean_up] [deepspeed] OVERFLOW! Rank 0 Skipping step. Attempted loss scale: 16384.0, reducing to 8192.0
1%|█▌ | 4/500 [00:02<05:00, 1.65it/s][2022-07-26 19:15:53,799] [INFO] [stage3.py:1834:_overflow_clean_up] [deepspeed] OVERFLOW! Rank 0 Skipping step. Attempted loss scale: 8192.0, reducing to 4096.0
1%|█▉ | 5/500 [00:03<04:16, 1.93it/s][2022-07-26 19:15:54,163] [INFO] [stage3.py:1834:_overflow_clean_up] [deepspeed] OVERFLOW! Rank 0 Skipping step. Attempted loss scale: 4096.0, reducing to 2048.0
1%|██▎ | 6/500 [00:03<03:49, 2.15it/s][2022-07-26 19:15:54,523] [INFO] [stage3.py:1834:_overflow_clean_up] [deepspeed] OVERFLOW! Rank 0 Skipping step. Attempted loss scale: 2048.0, reducing to 1024.0
2%|███▊ | 10/500 [00:05<03:37, 2.25it/s][2022-07-26 19:15:56,242] [INFO] [stage3.py:1834:_overflow_clean_up] [deepspeed] OVERFLOW! Rank 0 Skipping step. Attempted loss scale: 1024.0, reducing to 512.0
4%|███████▎ | 19/500 [00:09<03:33, 2.25it/s][2022-07-26 19:16:00,198] [INFO] [stage3.py:1834:_overflow_clean_up] [deepspeed] OVERFLOW! Rank 0 Skipping step. Attempted loss scale: 512.0, reducing to 256.0
35%|██████████████████████████████████████████████████████████████████▉ | 176/500 [01:18<02:23, 2.26it/s]
Multi-Node Deepspeed run with mistral
- Run the multi node deepspeed use case with mistral. Ensure that WANDB is disabled
- Enable the NCCL_DEBUG level to INFO to observe the messages
export NCCL_DEBUG=INFO
- Set the NCCL_SOCKET_IFNAME=eth0, otherwise it picks the first IP address for the container which is the container-eth0
export NCCL_SOCKET_IFNAME=eth0
- Run the deepspeed command from within the mistral folder to train a gpt2-small model (124 million parameters)
- Specify the Master IP Address (First IP in the /tmp/hostfile)
- Master Port can be anything between 0 - 65535
- Point the Hostfile to /tmp/hostfile
- Number of Nodes as 2 (since we started the training job with 2 nodes)
- It automatically downloads the data files, preprocess them and use it for training
root@ip-10-0-143-177:/workspace/mistral# deepspeed --num_gpus 1 --num_nodes 2 --master_addr 10.0.143.177 --master_port 33330 --hostfile /tmp/hostfile train.py --config conf/tutorial-gpt2-micro.yaml --nnodes 2 --nproc_per_node 1 --training_arguments.fp16 true --training_arguments.per_device_train_batch_size 4 --run_id tutorial-gpt2-micro-multi-node
[2022-07-26 22:43:03,683] [INFO] [multinode_runner.py:65:get_cmd] Running on the following workers: 10.0.143.177,10.0.128.14
[2022-07-26 22:43:03,683] [INFO] [runner.py:457:main] cmd = pdsh -S -f 1024 -w 10.0.143.177,10.0.128.14 export NCCL_VERSION=2.11.4-1; export NCCL_SOCKET_IFNAME=eth0; export NCCL_DEBUG=INFO; export PYTHONPATH=/workspace/mistral; cd /workspace/mistral; /usr/bin/python3 -u -m deepspeed.launcher.launch --world_info=eyIxMC4wLjE0My4xNzciOiBbMF0sICIxMC4wLjEyOC4xNCI6IFswXX0= --node_rank=%n --master_addr=10.0.143.177 --master_port=33330 train.py --config 'conf/tutorial-gpt2-micro.yaml' --nnodes '2' --nproc_per_node '1' --training_arguments.fp16 'true' --training_arguments.per_device_train_batch_size '4' --run_id 'tutorial-gpt2-micro-multi-node'
10.0.143.177: Warning: Permanently added '[10.0.143.177]:2022' (RSA) to the list of known hosts.
10.0.128.14: Warning: Permanently added '[10.0.128.14]:2022' (RSA) to the list of known hosts.
10.0.143.177: [2022-07-26 22:43:04,464] [INFO] [launch.py:96:main] 0 NCCL_VERSION=2.11.4-1
10.0.143.177: [2022-07-26 22:43:04,464] [INFO] [launch.py:96:main] 0 NCCL_SOCKET_IFNAME=eth0
10.0.143.177: [2022-07-26 22:43:04,464] [INFO] [launch.py:96:main] 0 NCCL_DEBUG=INFO
10.0.143.177: [2022-07-26 22:43:04,464] [INFO] [launch.py:103:main] WORLD INFO DICT: {'10.0.143.177': [0], '10.0.128.14': [0]}
10.0.143.177: [2022-07-26 22:43:04,464] [INFO] [launch.py:109:main] nnodes=2, num_local_procs=1, node_rank=0
10.0.143.177: [2022-07-26 22:43:04,464] [INFO] [launch.py:122:main] global_rank_mapping=defaultdict(<class 'list'>, {'10.0.143.177': [0], '10.0.128.14': [1]})
10.0.143.177: [2022-07-26 22:43:04,464] [INFO] [launch.py:123:main] dist_world_size=2
10.0.143.177: [2022-07-26 22:43:04,464] [INFO] [launch.py:125:main] Setting CUDA_VISIBLE_DEVICES=0
10.0.128.14: [2022-07-26 22:43:05,228] [INFO] [launch.py:96:main] 1 NCCL_VERSION=2.11.4-1
10.0.128.14: [2022-07-26 22:43:05,228] [INFO] [launch.py:96:main] 1 NCCL_SOCKET_IFNAME=eth0
10.0.128.14: [2022-07-26 22:43:05,228] [INFO] [launch.py:96:main] 1 NCCL_DEBUG=INFO
10.0.128.14: [2022-07-26 22:43:05,228] [INFO] [launch.py:103:main] WORLD INFO DICT: {'10.0.143.177': [0], '10.0.128.14': [0]}
10.0.128.14: [2022-07-26 22:43:05,228] [INFO] [launch.py:109:main] nnodes=2, num_local_procs=1, node_rank=1
10.0.128.14: [2022-07-26 22:43:05,228] [INFO] [launch.py:122:main] global_rank_mapping=defaultdict(<class 'list'>, {'10.0.143.177': [0], '10.0.128.14': [1]})
10.0.128.14: [2022-07-26 22:43:05,228] [INFO] [launch.py:123:main] dist_world_size=2
10.0.128.14: [2022-07-26 22:43:05,228] [INFO] [launch.py:125:main] Setting CUDA_VISIBLE_DEVICES=0
10.0.128.14: |=>> 07/26 [22:43:08] - mistral - INFO :: Downloading and Preprocessing Dataset `wikitext`...
10.0.143.177: |=>> 07/26 [22:43:52] - mistral - INFO :: Downloading and Preprocessing Online Eval Dataset wikitext
10.0.128.14: |=>> 07/26 [22:43:52] - mistral.corpora.auto - INFO :: Detokenizing Dataset via Multiprocessing with `4` threads...
10.0.143.177: |=>> 07/26 [22:43:53] - mistral - INFO :: Setting Training Arguments from Quinfig...
10.0.143.177: |=>> 07/26 [22:43:53] - mistral.args.training - INFO :: Setting Gradient Accumulation Steps = `4` [Node(s): 2 - GPU(s): 1 - Device BSZ: 4]
10.0.128.14: |=>> 07/26 [22:43:54] - torch.distributed.distributed_c10d - INFO :: Added key: store_based_barrier_key:1 to store for rank: 1
10.0.143.177: |=>> 07/26 [22:43:54] - torch.distributed.distributed_c10d - INFO :: Added key: store_based_barrier_key:1 to store for rank: 0
10.0.143.177: |=>> 07/26 [22:43:54] - torch.distributed.distributed_c10d - INFO :: Rank 0: Completed store-based barrier for key:store_based_barrier_key:1 with 2 nodes.
10.0.143.177: |=>> 07/26 [22:43:54] - mistral - INFO :: Initializing Model Trainer...
10.0.143.177: ip-10-0-143-177:2819:2819 [0] NCCL INFO Launch mode Parallel
10.0.143.177: |=>> 07/26 [22:43:56] - mistral.core.callbacks - INFO :: Automatic Weights & Biases logging enabled, to disable set os.environ["WANDB_DISABLED"] = "true"
10.0.143.177: |=>> 07/26 [22:43:56] - wandb - INFO :: Watching
0%| | 0/400000 [00:00<?, ?it/s][W reducer.cpp:1251] Warning: find_unused_parameters=True was specified in DDP constructor, but did not find any unused parameters in the forward pass. This flag results in an extra traversal of the autograd graph every iteration, which can adversely affect performance. If your model indeed never has any unused parameters in the forward pass, consider turning this flag off. Note that this warning may be a false positive if your model has flow control causing later iterations to have unused parameters. (function operator())
0%| | 0/400000 [00:00<?, ?it/s][W reducer.cpp:1251] Warning: find_unused_parameters=True was specified in DDP constructor, but did not find any unused parameters in the forward pass. This flag results in an extra traversal of the autograd graph every iteration, which can adversely affect performance. If your model indeed never has any unused parameters in the forward pass, consider turning this flag off. Note that this warning may be a false positive if your model has flow control causing later iterations to have unused parameters. (function operator())
10.0.128.14: {'loss': 10.9772, 'learning_rate': 1.5e-07, 'epoch': 0.0}
10.0.143.177: {'loss': 10.9772, 'learning_rate': 1.5e-07, 'epoch': 0.0}
10.0.128.14: {'loss': 10.5956, 'learning_rate': 7.499999999999999e-06, 'epoch': 0.0}
10.0.143.177: {'loss': 10.5956, 'learning_rate': 7.499999999999999e-06, 'epoch': 0.0}
10.0.128.14: {'loss': 9.495, 'learning_rate': 1.4999999999999999e-05, 'epoch': 0.01}
10.0.143.177: {'loss': 9.495, 'learning_rate': 1.4999999999999999e-05, 'epoch': 0.01}
10.0.128.14: {'loss': 8.7516, 'learning_rate': 2.2499999999999998e-05, 'epoch': 0.01}
10.0.143.177: {'loss': 8.7516, 'learning_rate': 2.2499999999999998e-05, 'epoch': 0.01}
10.0.128.14: {'loss': 8.0119, 'learning_rate': 2.9999999999999997e-05, 'epoch': 0.01}
10.0.143.177: {'loss': 8.0119, 'learning_rate': 2.9999999999999997e-05, 'epoch': 0.01}
10.0.128.14: {'loss': 7.5828, 'learning_rate': 3.75e-05, 'epoch': 0.02}
10.0.143.177: {'loss': 7.5828, 'learning_rate': 3.75e-05, 'epoch': 0.02}
10.0.128.14: {'loss': 7.4091, 'learning_rate': 4.4999999999999996e-05, 'epoch': 0.02}
10.0.143.177: {'loss': 7.4091, 'learning_rate': 4.4999999999999996e-05, 'epoch': 0.02}
10.0.128.14: {'loss': 7.2629, 'learning_rate': 5.2499999999999995e-05, 'epoch': 0.03}
10.0.143.177: {'loss': 7.2629, 'learning_rate': 5.2499999999999995e-05, 'epoch': 0.03}